

由谷歌研究院和谷歌DeepMind开发的一款新型人工智能系统,只要知道相机的位置,就能在短短几秒内将照片转化为逼真的3D场景。
该系统名为Bolt3D,在英伟达H100图形处理单元上仅需6.25秒,就能将照片处理成完整的三维场景,而其他系统完成这项任务通常需要几分钟甚至几小时。
Bolt3D首先确定每个像素在三维空间中的位置以及应有的颜色。然后,另一个模型会判定每个点的透明度,以及其在空间中的延展情况。
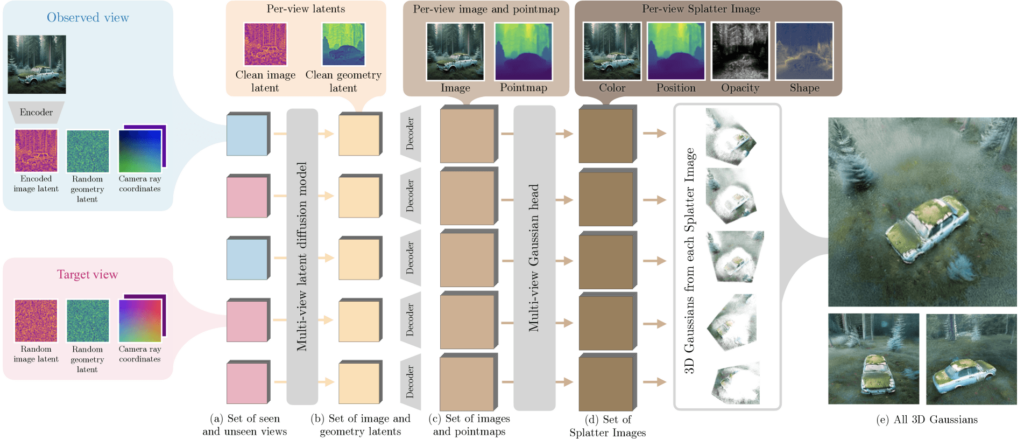
该系统依赖于一种名为“高斯溅射”的技术来存储数据,它利用布置在二维网格中的三维高斯函数来构建三维场景。每个函数都记录着位置、颜色、透明度和空间信息,这使得用户能够实时从任意角度查看该场景。为了使文件大小便于管理,该系统会去除透明区域,并对剩余的数据进行高效压缩。
开辟3D生成领域新天地
测试显示,Bolt3D的表现明显优于现有的诸如Flash3D和DepthSplat等快速方法。那些系统只能对其无法看到的区域进行模糊处理,而Bolt3D实际上能够为场景中隐藏的部分生成逼真的内容。
这种能力源自一个专门为处理空间数据而设计的人工智能模型——研究人员发现,仅在照片上训练的常规模型无法应对3D信息的复杂性。
为了构建这种能力,团队在约30万个3D场景上对Bolt3D进行了训练,这些场景包括基于照片的重建模型以及计算机生成的模型。这个庞大的数据集帮助该系统对其无法完全看清的场景部分做出合理推测。

该系统仍然存在局限性。它在处理非常精细的细节(宽度小于8个像素的任何物体)、像玻璃这样的透明材质以及高度反光的表面时会遇到困难。最终生成结果的质量也在很大程度上取决于照片的拍摄方式以及最终场景所需的大小。
尽管存在这些局限,Bolt3D似乎在3D内容创作方面向前迈进了一步。相关论文指出,它的处理速度首次使得大规模3D场景生成变得切实可行。虽然目前尚未公布该系统是否会向公众开放,但感兴趣的用户可以在该项目的网站上找到更多信息以及交互式演示。
在Bolt3D系统开发的同时,Stability AI公司发布了其自主研发的SPAR3D系统,该系统同样能够快速地从单张图像生成3D物体。二者的关键区别在于:SPAR3D处理的是单个物体,而Bolt3D能够处理整个场景。