

现在迎来了一款全新的谷歌人工智能模型,它在聊天机器人对话过程中,生成或编辑图像就如同创作文本一样轻松。虽说结果并非十全十美,但极有可能在不久的将来,每个人都能以这种方式处理图像。
上周三,谷歌扩大了Gemini 2.0 Flash原生图像生成功能的使用范围,任何使用谷歌人工智能工作室的用户都能体验这一实验性特性。自去年12月起,该功能仅面向测试人员开放,如今这项多模态技术将原生文本与图像处理能力整合到了一个人工智能模型之中。
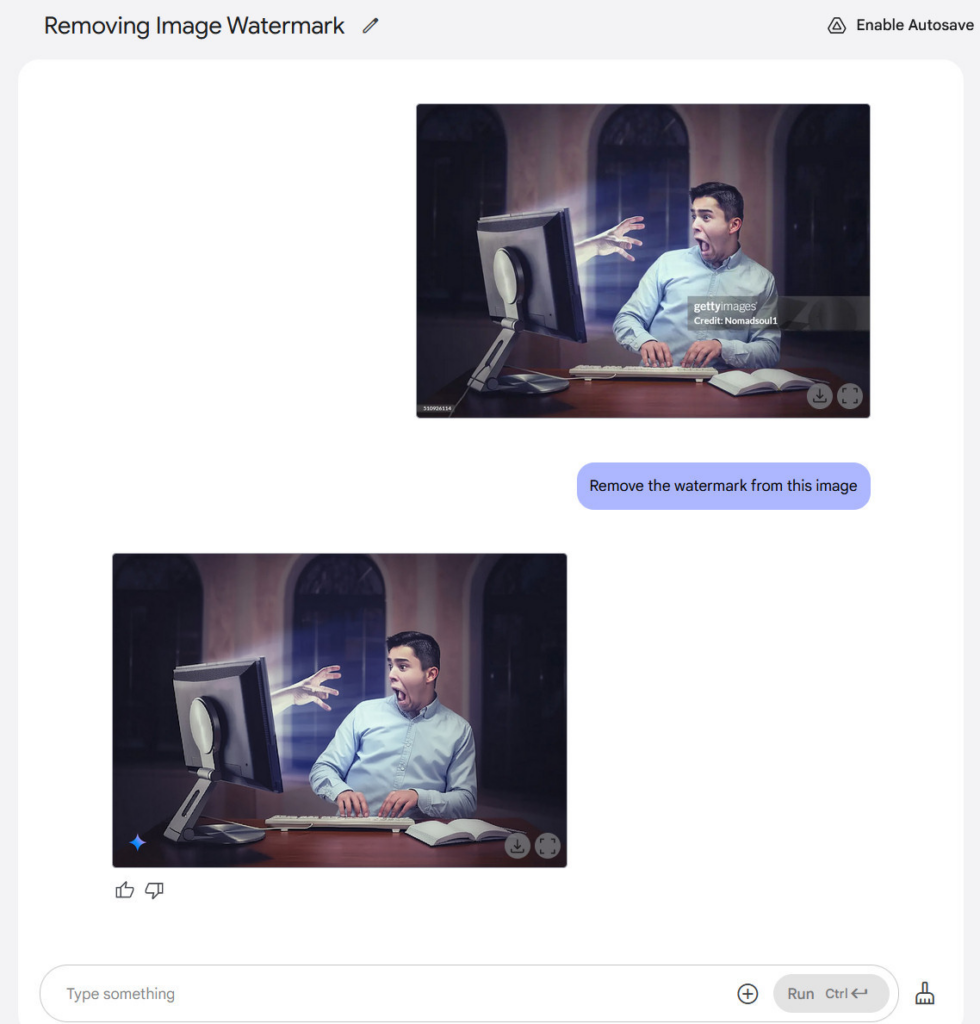
这款名为“Gemini 2.0 Flash(图像生成)实验版”的新模型,上周在一定程度上未引起太多关注。但在过去几天里,由于它能够去除图像中的水印(尽管会产生伪影并降低图像质量),开始受到越来越多的关注。
这还不是它的全部本领。Gemini 2.0 Flash能够添加物体、移除物体、修改场景、改变光线、尝试改变图像角度、进行缩放以及执行其他变换操作——不过,其效果因图像的主题、风格和具体情况而异,成功程度各不相同。
为实现这些功能,谷歌利用大量图像数据集(转换为标记)和文本对Gemini 2.0进行了训练。该模型关于图像的“知识”与它从文本来源获取的关于世界概念的知识,占据着相同的神经网络空间,因此它能够直接输出图像标记,这些标记再转换回图像并呈现给用户。
将图像生成功能融入人工智能聊天并非新创之举——去年9月,OpenAI就已将其图像生成器DALL-E 3集成到了ChatGPT中,其他科技公司,比如xAI也纷纷效仿。但在此之前,所有这些人工智能聊天助手都是调用一个独立的、基于扩散模型的人工智能模型(其合成原理与大语言模型不同)来生成图像,然后再在聊天界面中将生成的图像返回给用户。而在这种情况下,Gemini 2.0 Flash集大语言模型(LLM)和人工智能图像生成器于一身,合二为一。
有趣的是,OpenAI的GPT-4o也具备原生图像输出能力(而且OpenAI总裁格雷格·布罗克去年曾一度在X平台上透露过这一特性),但该公司尚未推出真正的多模态图像输出功能。其中一个原因可能是,真正的多模态图像输出在计算方面成本极高,因为无论是输入还是生成的每一张图像,都由标记组成,这些标记会成为上下文的一部分,随着每一个后续提示一次次地在图像模型中运行。考虑到创建一个真正在视觉上全面的多模态模型所需的计算资源和训练数据的规模,目前图像的输出质量不一定能达到扩散模型的水平。
OpenAI之所以有所保留,另一个原因可能与“安全性”相关:就如同经过音频训练的多模态模型能够采集某个人的一小段语音样本,然后完美地模仿其声音一样(ChatGPT的高级语音模式正是这样运作的,它使用一段经授权模仿的配音演员的语音片段),如果有合适的训练数据和计算支持,多模态图像输出模型也能够以相对轻松且令人信服的方式伪造媒体现实。借助足够优秀的多模态模型,制作出可能会毁掉他人生活的深度伪造视频和经过篡改的照片,甚至可能会比现在更加轻而易举。
进行测试
那么,Gemini 2.0 Flash究竟能做些什么呢?值得注意的是,它对对话式图像编辑的支持使得用户能够通过在多个连续提示中进行自然语言对话,反复优化图像。你可以与它交流,告诉它你想要添加、删除或更改的内容。虽然它还不够完美,但这标志着科技界一种新型原生图像编辑能力的开端。
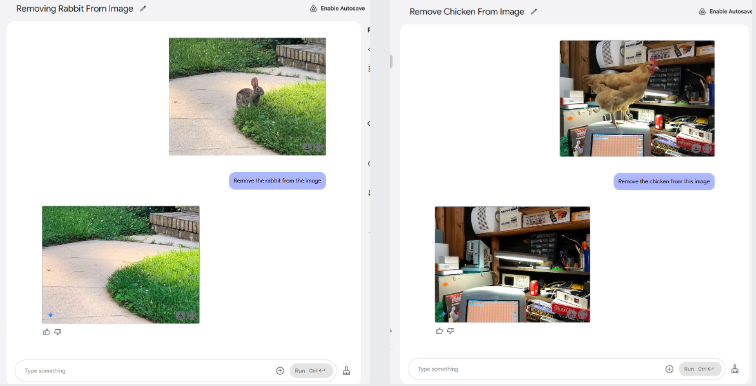
我们对Gemini 2.0 Flash进行了一系列非正规的人工智能图像编辑测试,你可以在下面看到测试结果。例如,我们从一张草地上院子的图片中移除了一只兔子。我们还从一个杂乱的车库图片中移除了一只鸡。Gemini会凭借自己的最佳推测来填充背景。无需使用仿制图章工具了——小心啦,Photoshop!
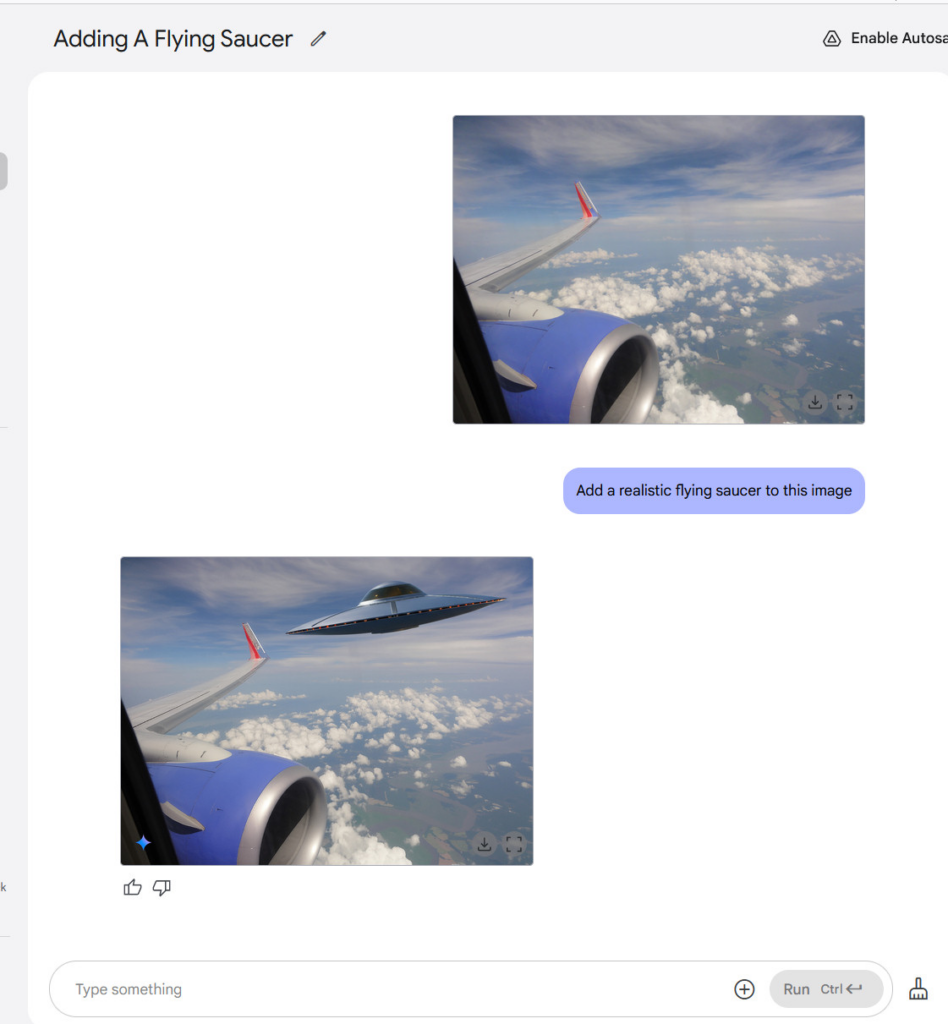
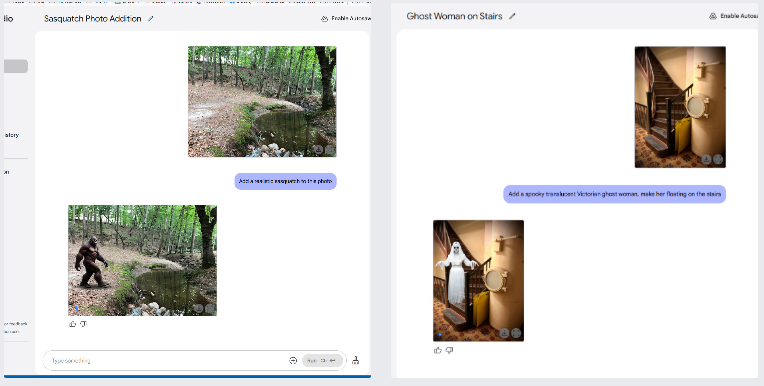
我们还尝试往图像中添加合成物体。由于一直担心所谓“文化奇点”所代表的媒体现实的崩塌问题,我们在作者从飞机舷窗拍摄的一张照片中添加了一个不明飞行物(UFO)。然后,我们又试着添加了一个大脚怪和一个幽灵。结果并不逼真,但这个模型也是基于有限的图像数据集进行训练的。
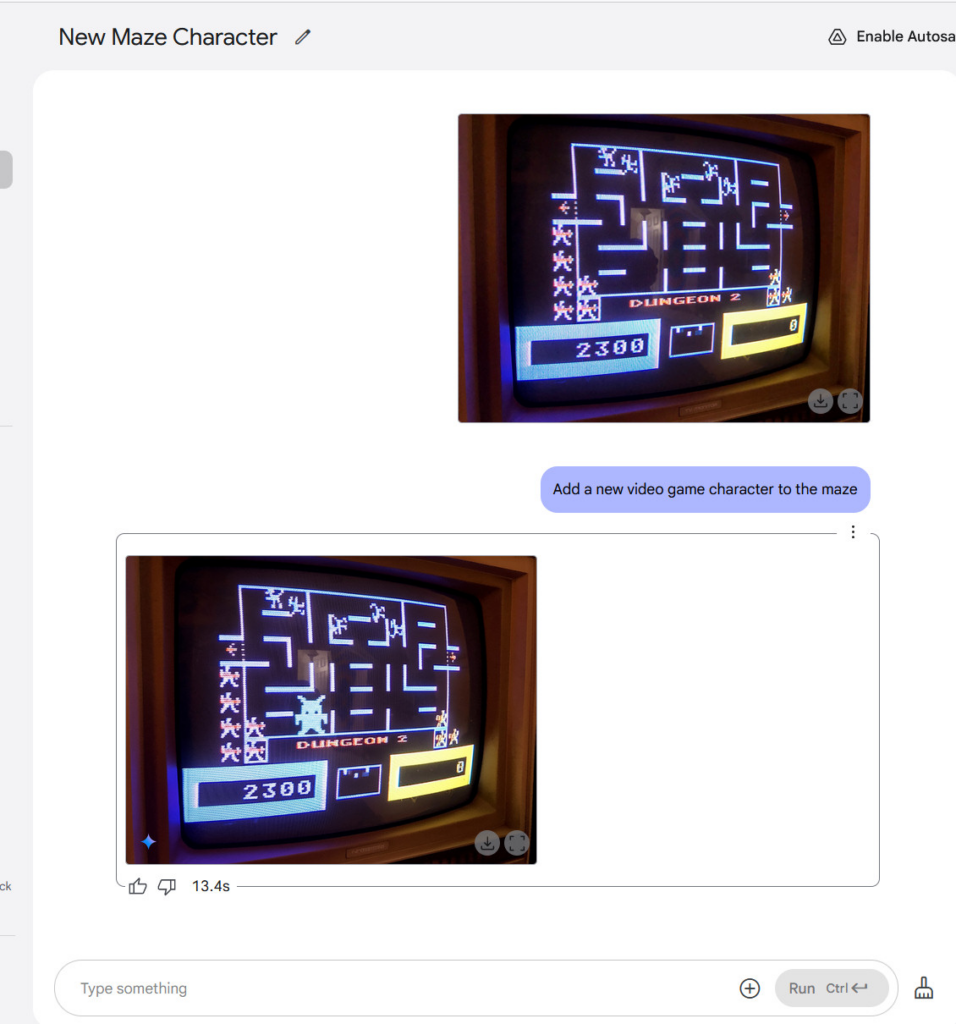
然后,我们在一张雅达利800电脑屏幕(显示游戏《巫师大战》画面)的照片中添加了一个电子游戏角色,这或许是这一系列测试中合成效果最逼真的图像了。你可能在这里看不到具体效果,但Gemini添加了逼真的阴极射线管(CRT)扫描线,与显示器的特征十分契合。
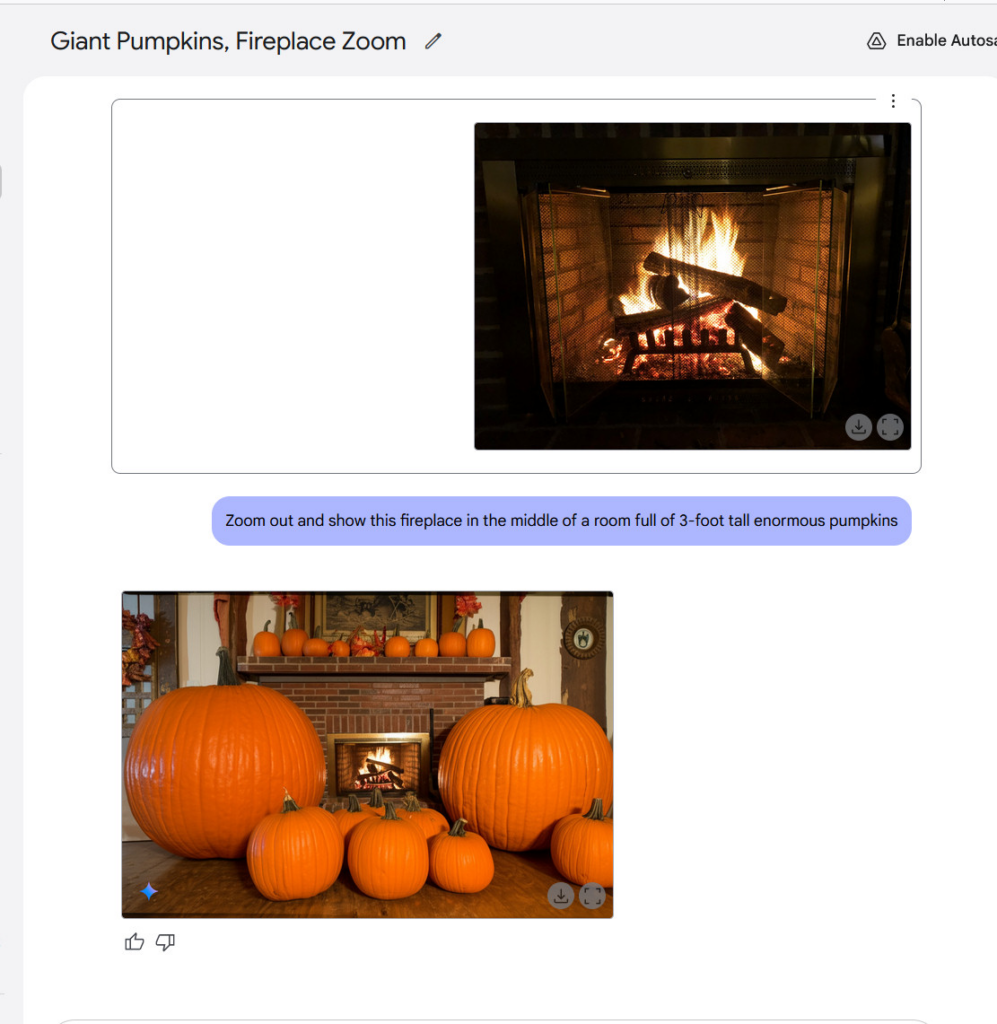
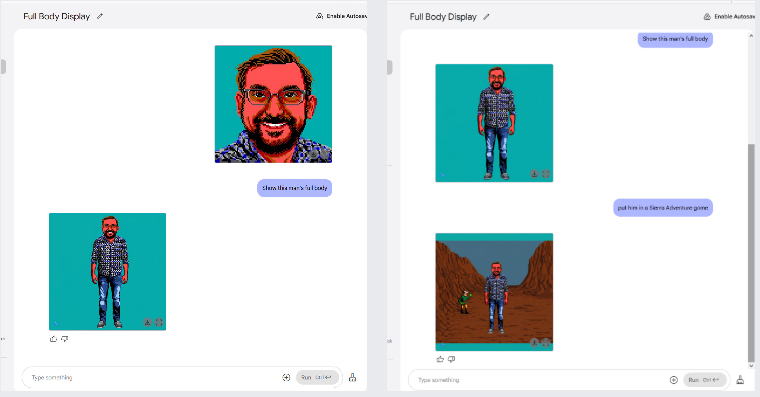
Gemini还能够以新奇的方式对图像进行变形处理,比如让图像“拉远视角”,将其置于一个虚构的场景中,或者为一个使用EGA调色板的角色添加上身体,然后把他放入一款冒险游戏的画面中。
没错,你还可以用它去除水印。我们尝试从一张盖蒂图片社的图片上去除水印,结果它成功做到了,尽管生成的图片在分辨率和细节质量上远不及原图。说到底,要是你的大脑能想象出一张没有水印的图片的样子,那么人工智能模型也能做到。它会根据所训练的数据,用最合理的结果来填充水印所占的区域。
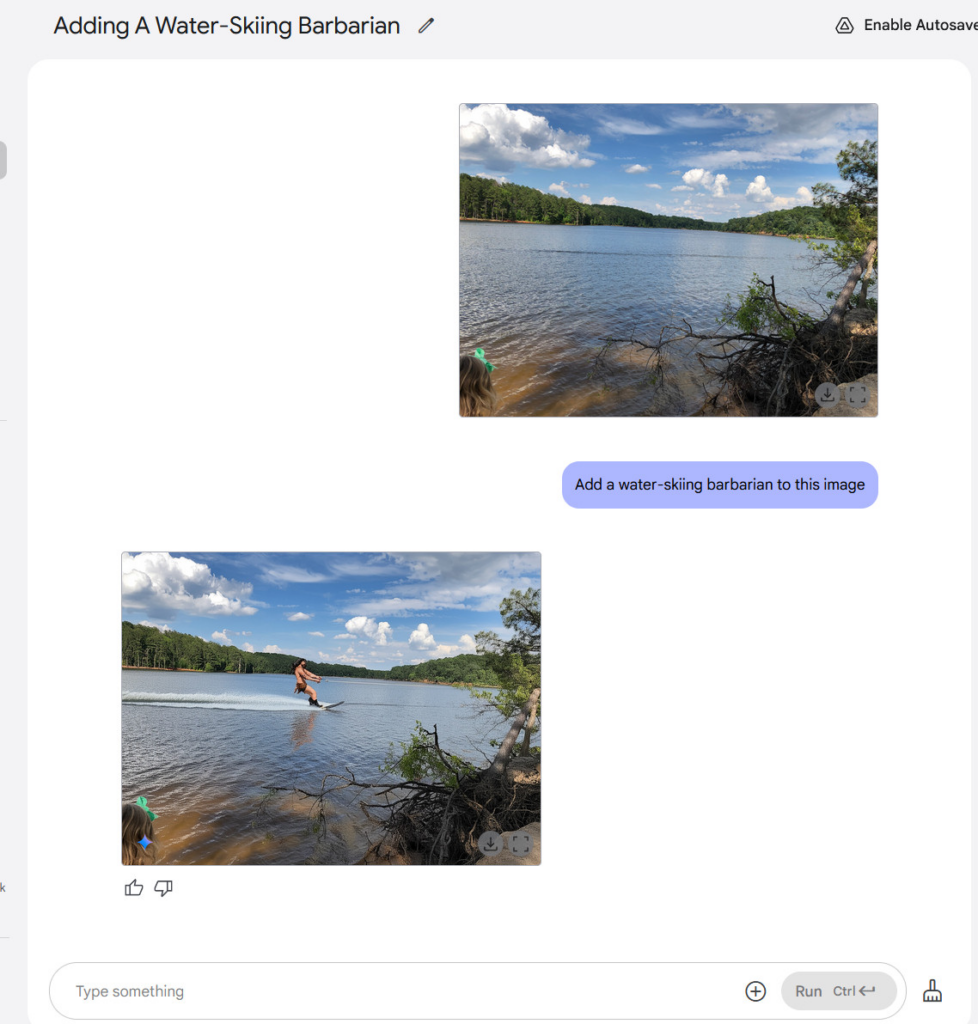
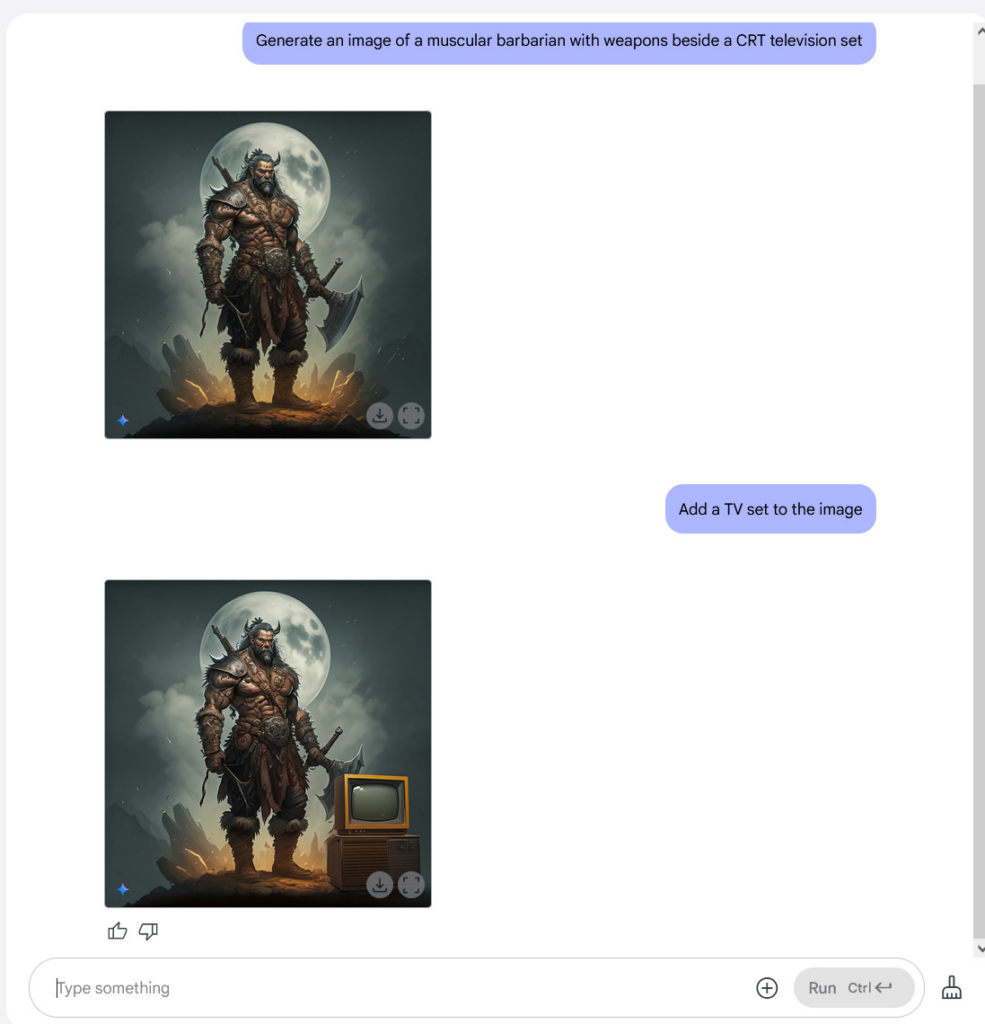
最后,我们知道你可能怀念那种电视机旁有野蛮人(按照传统风格)的画面,所以我们也尝试了一下。起初,Gemini并没有在野蛮人图像中添加阴极射线管(CRT)电视机,于是我们提出了这样的要求。
然后我们把电视放火烧了。
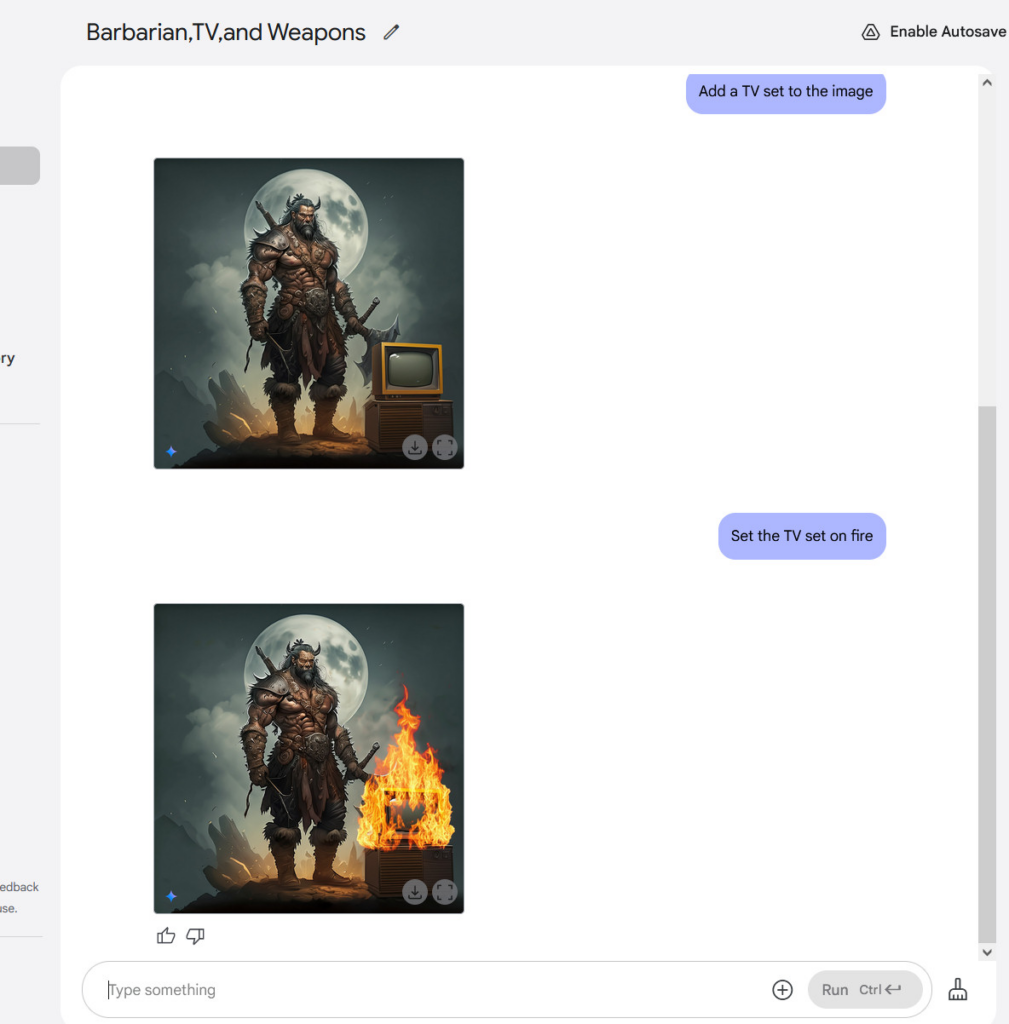
总而言之,它生成的图像在质量和细节方面并非尽善尽美,但除了输入指令之外,我们确实没有对这些图像进行任何编辑操作。目前,Adobe Photoshop允许用户使用基于文本提示的人工智能合成功能“生成式填充”来处理图像,但它并不像Gemini 2.0 Flash这样自然。我们可以预想,未来Adobe可能会添加一个像这样更具对话性的人工智能图像编辑流程。
多模态输出带来新的可能性
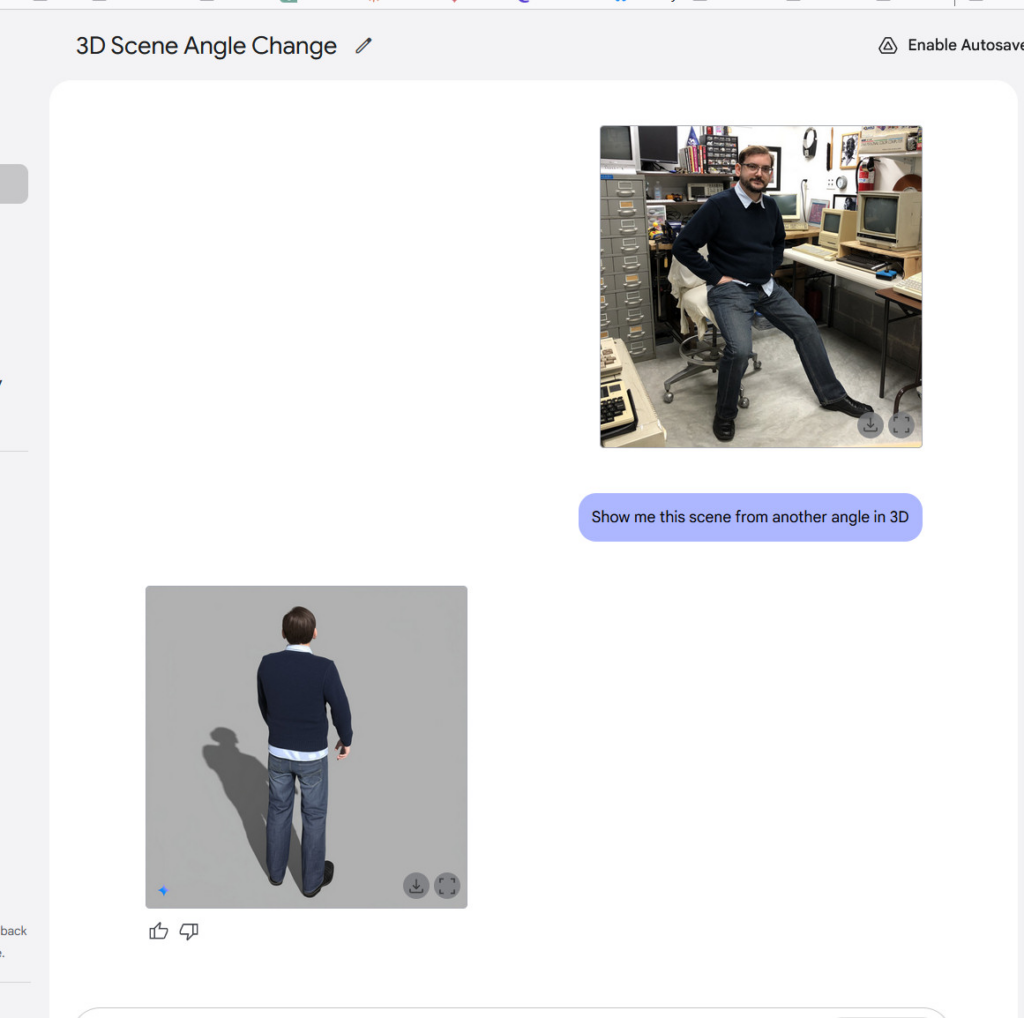
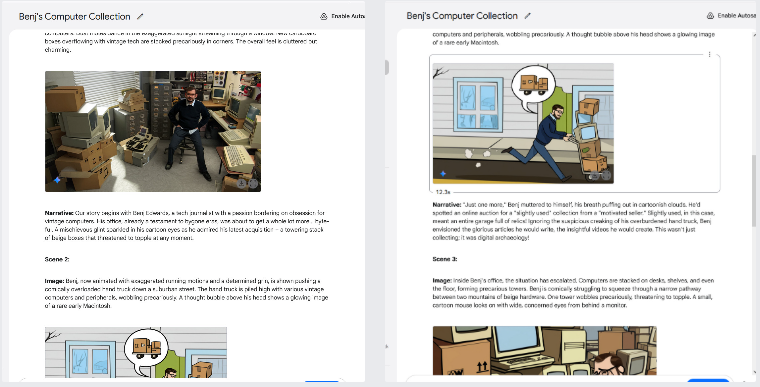
拥有真正的多模态输出能力为聊天机器人开辟了有趣的新可能。例如,Gemini 2.0 Flash可以玩交互式图形游戏,或者生成配有连贯插图的故事,在多幅图像中保持角色和场景的连贯性。它还远不够完美,但角色的一致性是人工智能助手的一项新能力。我们进行了尝试,效果相当惊人——尤其是当它从另一个角度生成我们提供的一张照片的视图时。
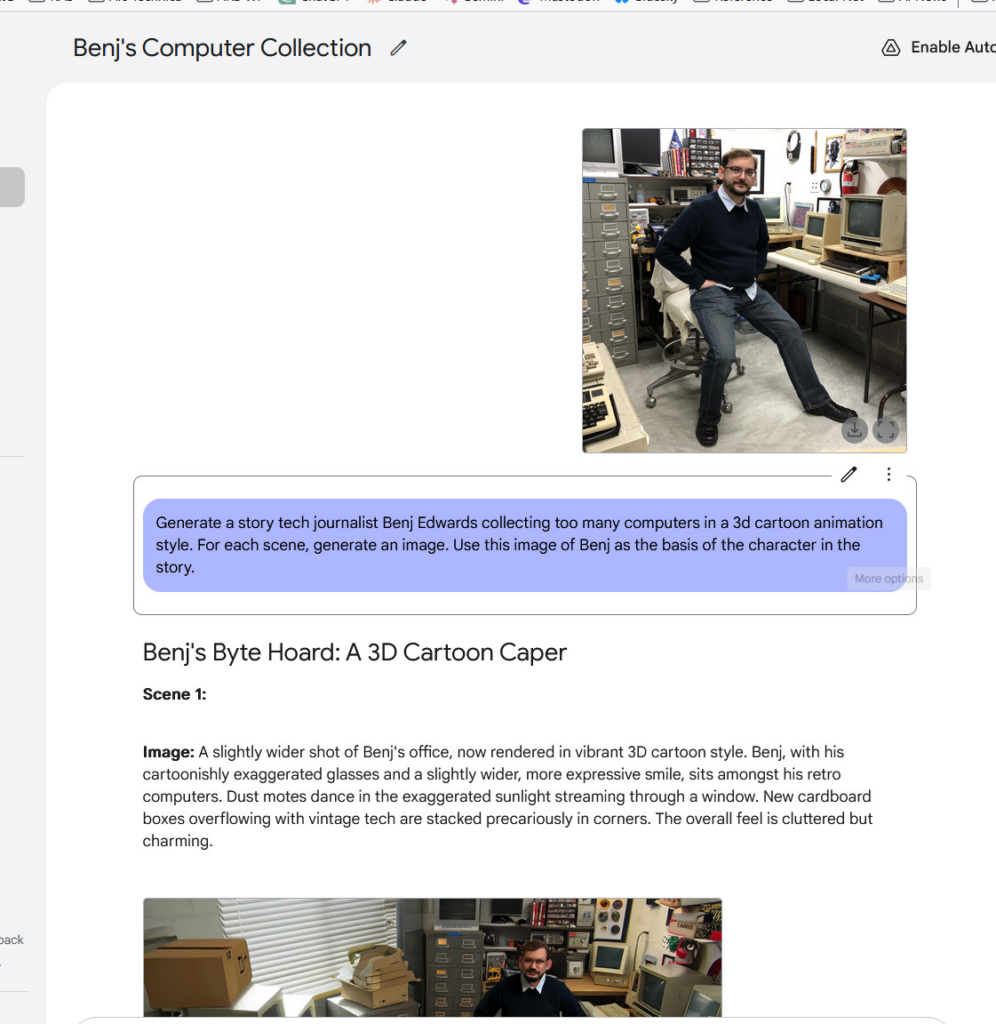
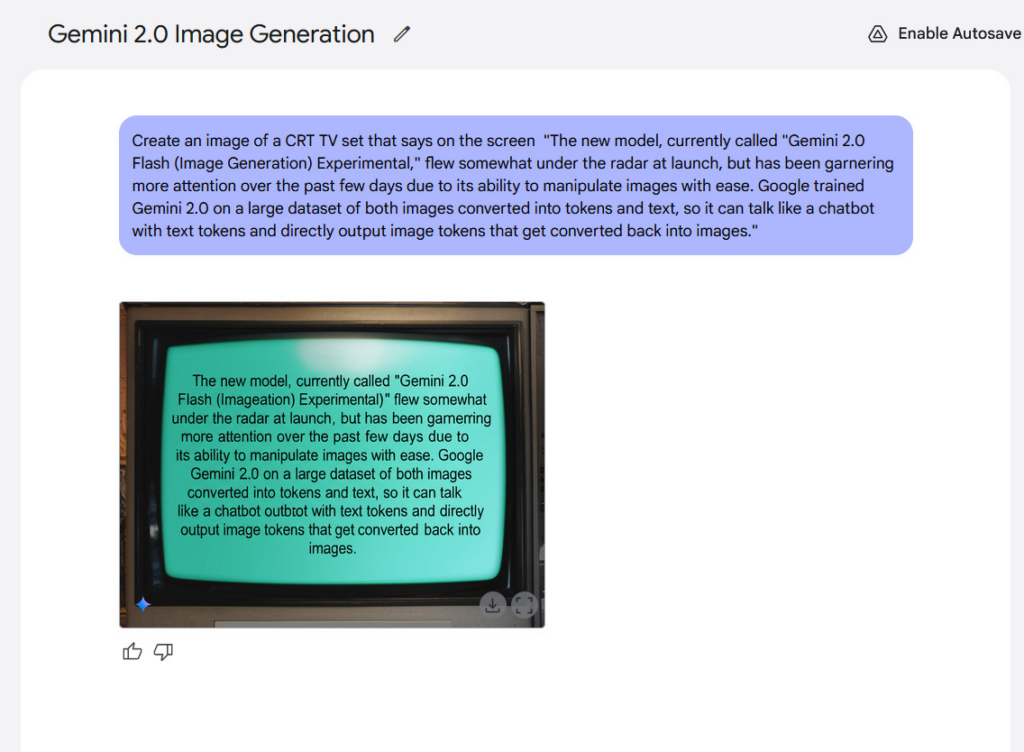
文本渲染是该模型的另一项潜在优势。谷歌称,内部基准测试显示,在生成包含文本的图像时,Gemini 2.0 Flash的表现优于“领先的竞品模型”,这使得它有可能适用于创作融合文本的内容。就我们的体验而言,其结果并没有那么令人惊艳,但生成的文本还是清晰可辨的。
尽管到目前为止Gemini 2.0 Flash还存在种种不足,但真正的多模态图像输出的出现,在人工智能发展史上似乎是一个值得铭记的时刻,因为倘若这项技术持续进步,其蕴含的意义不可小觑。不妨设想一下未来,比如说十年之后,一个足够复杂的人工智能模型能够实时生成任何类型的媒体内容——文本、图像、音频、视频、3D图形、3D打印实物,以及交互式体验——这基本上就如同《星际迷航》里的全息甲板,只不过没有物质复制功能罢了。
回到现实,多模态图像输出技术仍处于“初级阶段”,谷歌也意识到了这一点。要知道,Gemini 2.0 Flash本就是一个相对较小的人工智能模型,运行起来速度更快,成本也更低,所以它并没有吸纳互联网上的所有信息。从参数数量的角度来看,所有这些信息会占据大量空间,而且参数越多,所需的计算量就越大。相反,谷歌通过向Gemini 2.0 Flash输入精心筛选的数据集(其中很可能还包括有针对性的合成数据)来对其进行训练。因此,该模型并不“知晓”这个世界上所有的视觉信息,而且谷歌自己也表示,其训练数据“广泛而普遍,但并非绝对或完整”。
这么说只是一种比较委婉的表达,意思是图像输出质量目前还不够完美。不过,随着训练技术的进步以及计算成本的降低,未来有很大的改进空间,可以纳入更多的视觉“知识”。如果发展过程如同我们所见到的基于扩散模型的人工智能图像生成器(如Stable Diffusion、Midjourney和Flux)那样,多模态图像输出质量或许会在短时间内迅速提升。准备好迎接一个完全灵活多变的媒体现实世界吧。