
汽车设计是一个迭代且具有独创性的过程。汽车制造商通常需要数年时间来进行设计阶段,通过在仿真中不断调整三维模型,然后将最有潜力的设计转化为实际物理测试。然而,这些测试的细节和规格,包括汽车设计的空气动力学特性,通常不会公开。因此,诸如燃油效率或电动汽车续航等性能方面的重大进展往往会非常缓慢,并且各公司之间的进展彼此隔离。
麻省理工学院的工程师表示,借助生成式人工智能工具,可以显著加速汽车设计的探索过程,因为这些工具能够在几秒钟内处理大量数据,发现其中的联系,从而生成新颖的设计。虽然此类AI工具已经存在,但它们所需的数据过去一直没有以可访问、集中的形式公开。
然而,现在,这些工程师首次将这样的数据集公开了。这个名为DrivAerNet++的数据集包含了超过8,000个汽车设计,这些设计基于当前世界上最常见的车型类型。相关研究已发布在arXiv预印本服务器上。
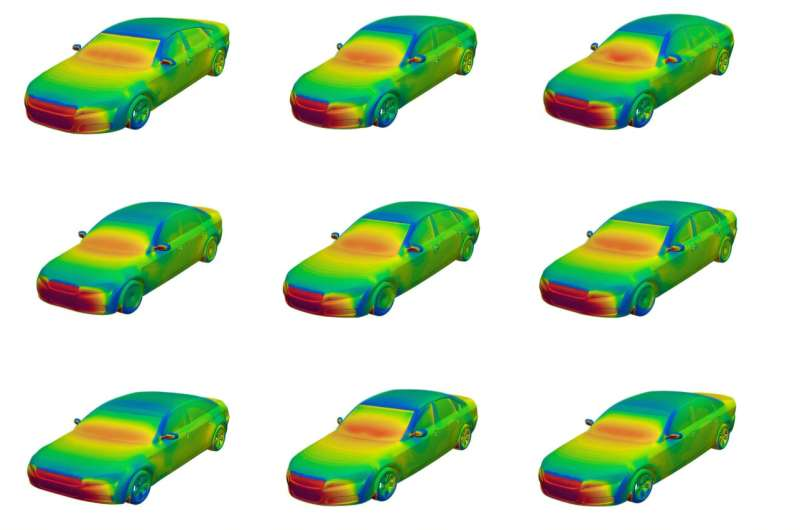
每个设计都以三维形式呈现,并包含有关汽车空气动力学的信息——即空气如何在特定设计周围流动,这些数据基于该小组为每个设计所进行的流体动力学仿真。
数据集中包含的8,000个设计,每个都可以以多种形式呈现,如网格、点云,或简单的设计参数和尺寸列表。因此,该数据集可以被不同的AI模型使用,这些模型已调优以处理特定类型的数据。
DrivAerNet++是迄今为止开发的最大的开源汽车空气动力学数据集。工程师们设想该数据集作为一个庞大的现实汽车设计库,提供详细的空气动力学数据,可用于快速训练任何AI模型。随后,这些模型可以迅速生成新颖的设计,从而有可能在比今天汽车行业所需的时间短得多的时间内,创造出更具燃油效率和更长续航里程的电动汽车。
“这个数据集为下一代AI工程应用奠定了基础,促进了高效的设计过程,降低了研发成本,并推动了迈向更加可持续汽车未来的进展。”麻省理工学院机械工程研究生Mohamed Elrefaie说道。
Elrefaie和他的同事将在2024年12月的温哥华NeurIPS会议上介绍一篇论文,详细阐述这一新数据集以及可应用于该数据集的AI方法。他的合著者包括麻省理工学院机械工程助理教授Faez Ahmed,慕尼黑工业大学计算机科学副教授Angela Dai,以及BETA CAE Systems的Florin Marar。
填补数据空白
Ahmed领导着麻省理工学院的设计计算与数字工程实验室(DeCoDE),他的团队探索如何利用AI和机器学习工具来提升复杂工程系统和产品的设计,包括汽车技术。
“在设计汽车时,前期过程往往如此昂贵,以至于制造商只能在不同版本之间对汽车做一些微小的调整。”Ahmed说,“但如果你拥有更大的数据集,知道每个设计的性能,那么你就可以训练机器学习模型进行快速迭代,这样你就更有可能得到一个更好的设计。”
速度,特别是在推动汽车技术进步方面,现在显得尤为迫切。
“这是加速汽车创新的最佳时机,因为汽车是世界上最大的污染源之一,我们能越快减少它们的贡献,就能越多地帮助气候。”Elrefaie说。
在研究新汽车设计的过程中,研究人员发现,尽管已有一些AI模型可以处理大量汽车设计,以生成最优设计,但实际上可用的汽车数据却十分有限。一些研究人员此前曾整理出小型的汽车设计模拟数据集,但汽车制造商很少发布他们探索、测试并最终生产的实际设计规格。
该团队旨在填补数据空白,特别是在汽车空气动力学方面,因为空气动力学在决定电动汽车续航里程和内燃机汽车燃油效率方面起着关键作用。团队意识到,挑战在于如何组建一个包含成千上万个汽车设计的数据集,每个设计在功能和外形上都要做到物理准确,但又没有实际测试和测量其性能的优势。
为了构建一个具有物理准确性、能够真实表现空气动力学特性的汽车设计数据集,研究人员首先使用了2014年奥迪和宝马提供的几个基准三维模型。这些模型代表了三种主要类型的乘用车:快背式(后部倾斜的轿车)、轿背式(后部轮廓略有下凹的轿车或轿跑车)和旅行背式(如尾部较为平坦的旅行车)。
这些基准模型被认为填补了简单设计和更复杂专有设计之间的空白,并且已被其他团队用作探索新汽车设计的起点。
汽车图书馆
在新研究中,团队对每个基准汽车模型应用了形态变换操作。该操作系统地对每个汽车设计中的26个参数进行了轻微调整,例如车长、底盘特征、挡风玻璃坡度和轮胎宽度,然后将这些调整后的设计标记为一个独特的汽车设计,并将其添加到不断增长的数据集中。
与此同时,团队运行了一种优化算法,确保每个新设计确实是独特的,而不是已经生成的设计的复制品。随后,他们将每个三维设计转换为不同的表示方式,使得每个设计可以作为网格、点云或尺寸和规格列表进行表示。
研究人员还进行了复杂的计算流体动力学仿真,计算空气如何流过每个生成的汽车设计。最终,这项工作产生了超过8,000个独特的、物理准确的三维汽车模型,涵盖了当今道路上最常见的乘用车类型。
为了生成这个全面的数据集,研究人员使用麻省理工学院的SuperCloud平台耗费了超过300万CPU小时,并生成了39TB的数据。(作为对比,估计整个国会图书馆的印刷藏书大约为10TB的数据。)
工程师表示,研究人员现在可以利用这个数据集来训练特定的AI模型。例如,AI模型可以在数据集的一部分上进行训练,以学习具有某些理想空气动力学特性的汽车配置。基于从数据集中的成千上万个物理准确的设计中学到的知识,模型可以在几秒钟内生成一个具有优化空气动力学的新汽车设计。
研究人员还表示,该数据集也可以用于反向目标。例如,在使用数据集训练AI模型后,设计师可以向模型输入一个特定的汽车设计,并让模型迅速估算该设计的空气动力学特性,然后利用这些估算来计算汽车的潜在燃油效率或电动续航里程——这一切都无需进行昂贵的物理汽车制造和测试。
“这个数据集使你能够训练生成式AI模型,在几秒钟内完成任务,而不是几小时。”Ahmed说,“这些模型可以帮助降低内燃机汽车的燃油消耗,并增加电动汽车的续航里程——最终为更可持续、环保的汽车铺平道路。”