

一项新研究提出了一种改进潜在扩散模型(如Stable Diffusion)生成图像质量的方法。
该方法的核心在于优化图像的显著区域,即最能吸引人类注意力的部分。

传统方法通常对整个图像进行均匀优化,而新方法则借助显著性检测器来识别并优先处理更“重要”的区域,模仿人类的视觉方式。
在定量和定性测试中,研究人员的方法在图像质量和与文本提示的匹配度方面均优于之前的基于扩散模型的算法。
在一项有100名参与者的人类感知测试中,该新方法也取得了最佳成绩。
自然选择
显著性,即在现实世界和图像中优先处理信息的能力,是人类视觉的核心部分。
一个简单的例子是经典艺术中对重要区域的细节处理,如肖像画中对面部的关注,或海景画中对船帆的强调;在这些例子中,艺术家的注意力集中在核心主题上,这意味着广泛的背景细节,如肖像的背景或远处的风暴海浪,通常较为粗略和概括。
受人类研究的启发,过去十年中出现了可以复制或至少近似这种人类兴趣焦点的机器学习方法。

在过去五年的研究文献中,最受欢迎的显著性图检测器是2016年提出的梯度加权类激活映射(Grad-CAM)方法,后来演变为改进版Grad-CAM++,以及其他变体和优化。
Grad-CAM通过语义标记(如“狗”或“猫”)的梯度激活来生成一个视觉映射,显示概念或注释在图像中可能出现的位置。
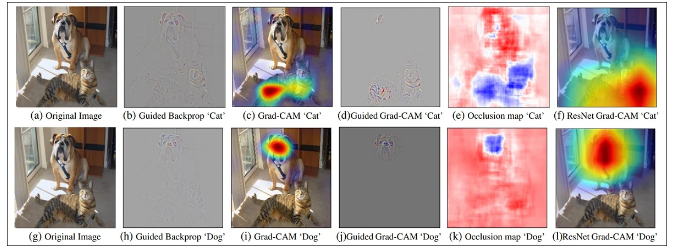
人类调查研究表明,这些方法所获得的关键兴趣点与人类在观察图像时的注意力分布存在高度一致性。
SGOOL(显著性引导优化)
这篇新论文探讨了显著性在文本生成图像(以及可能的文本生成视频)系统中,如Stable Diffusion和Flux,能够带来的优势。
当解释用户的文本提示时,潜在扩散模型(LDM)会在其训练过的潜在空间中搜索与单词或短语相对应的视觉概念。随后,这些找到的数据点会经过一个去噪过程,即逐步将随机噪声演变为用户文本提示的创意解读。
然而,在这一过程中,模型对图像的每个部分都给予了相同的注意力。自2022年扩散模型普及以来(伴随着OpenAI推出DALL-E图像生成器,以及Stability.ai开源Stable Diffusion框架),用户发现图像中的“关键”部分往往得不到应有的重视。
考虑到在典型的人物描绘中,人脸(对观看者至关重要的部分)通常只占图像总面积的10-35%,这种平均分配注意力的方式违背了人类感知的本质以及艺术和摄影的历史。
当人物牛仔裤上的纽扣与他们的眼睛被分配相同的计算资源时,可以说这种资源分配并不优化。
因此,研究作者提出了一种名为“显著性引导的扩散潜变量优化(SGOOL)”的新方法。该方法通过显著性映射器增强对图像中被忽视部分的关注,将较少的计算资源分配给那些可能位于观看者注意力边缘的区域。
方法
SGOOL的工作流程包括图像生成、显著性映射和优化,并对整体图像和显著性优化后的图像进行联合处理。
扩散模型的潜变量嵌入通过直接微调进行优化,省去了训练特定模型的需求。斯坦福大学的去噪扩散隐式模型(DDIM)采样方法,在Stable Diffusion用户中广为人知,已被改进以结合显著性图提供的次要信息。
论文中指出:
“我们首先使用显著性检测器模拟人类视觉注意系统,标记出显著区域。为了避免重新训练额外的模型,我们的方法直接优化扩散潜变量。
此外,SGOOL利用了可逆的扩散过程,并具备恒定内存实现的优势。因此,我们的方法成为了一种参数高效且即插即用的微调方法。我们进行了大量实验,使用了多个指标和人类评估。”
由于此方法需要多次迭代去噪过程,作者采用了“扩散潜变量直接优化”(DOODL)框架,该框架提供了可逆的扩散过程——虽然它仍然对图像的每个部分施加注意力。
为了定义人类的兴趣区域,研究人员使用了邓迪大学2022年发布的TransalNet框架。
由TransalNet处理的显著区域随后被裁剪,生成最有可能引起人类兴趣的显著部分。
在定义损失函数时,需要考虑用户文本和图像之间的差异,以判断过程是否有效。为此,研究人员使用了OpenAI的对比语言-图像预训练模型(CLIP)的版本,这一模型现已成为图像合成研究领域的核心工具之一。同时,还考虑了文本提示与全局(非显著性)图像输出之间的语义距离。
作者表示:
“最终的损失函数同时考虑了显著部分与全局图像之间的关系,有助于在生成过程中平衡局部细节和全局一致性。
这种显著性感知的损失被用于优化图像潜变量。梯度是在加噪的潜变量上计算的,并用于增强输入提示在原始生成图像显著和全局方面的调节效果。”
数据与测试
为了测试SGOOL,作者使用了Stable Diffusion V1.4的“原始”分布(在测试结果中表示为“SD”)以及带有CLIP引导的Stable Diffusion(在结果中表示为“baseline”)。
系统针对三个公共数据集进行了评估:CommonSyntacticProcesses(CSP)、DrawBench和DailyDallE*。
DailyDallE包含来自OpenAI博客文章中的一位艺术家的99个精细提示,而DrawBench则提供了11个类别下的200个提示。CSP由基于八种不同语法案例的52个提示组成。
在SD、baseline和SGOOL的测试中,CLIP模型使用ViT/B-32生成图像和文本嵌入。所有实验中使用相同的提示和随机种子,输出尺寸为256×256,TransalNet的默认权重和设置被应用。
除了CLIP评分标准外,研究还采用了估算的“人类偏好评分”(HPS),并进行了有100名参与者的真实世界测试。
关于上表中量化结果,论文指出:
“[我们的]模型在所有数据集上的CLIP评分和HPS指标上都显著优于SD和Baseline。我们模型在CLIP评分和HPS上的平均结果分别比第二名高出3.05和0.0029。”
作者进一步估算了HPS和CLIP评分相对于以往方法的箱线图:
他们评论道:
“可以看出,我们的模型优于其他模型,表明它更能生成与提示一致的图像。
然而,由于该评估指标的范围为 [0, 1],在箱线图中很难直观地比较。因此,我们接着绘制了相应的柱状图。
可以看出,SGOOL在所有数据集上的CLIP评分和HPS指标都优于SD和Baseline。量化结果表明,我们的模型能够生成更具语义一致性且更符合人类偏好的图像。”
研究人员指出,虽然Baseline模型能够提高图像输出的质量,但它没有考虑图像的显著区域。研究人员主张,SGOOL在全局与显著区域的图像评估之间达成平衡,从而获得了更好的图像。
在定性(自动化)比较中,SGOOL和DOODL的优化次数设定为50次。
作者观察到:
“在[第一行]中,提示的主体是‘一只猫在唱歌’和‘一个理发店四重唱’。SD生成的图像中有四只猫,图像内容与提示的对齐程度较差。
Baseline生成的图像忽略了猫,且面部描绘和图像细节缺乏表现力。DOODL尝试生成与提示一致的图像。
然而,由于DOODL直接优化整个图像,导致图像中的人物被优化成了猫的样子。”
他们进一步指出,与之相比,SGOOL生成的图像与原始提示更加一致。
在人类感知测试中,100名志愿者对测试图像的质量和语义一致性进行了评估(即图像与其源文本提示的吻合程度)。参与者在做出选择时没有时间限制。
正如论文所指出的,作者的方法明显优于之前的各类方法,并在测试中得到了更多的偏爱。
结论
在论文中讨论的问题在本地安装的Stable Diffusion中显现后,不久就出现了各种定制化方法(如After Detailer),这些方法强制系统对人类更感兴趣的区域给予更多关注。
然而,这种方法要求扩散系统首先按照常规流程对图像的每个部分平均分配注意力,然后在额外的阶段进行更多处理。
SGOOL的证据表明,通过将人类基本心理学应用于图像区域的优先级分配,可以极大地增强初始推理过程,而无需后期处理步骤。