
背景
你可能见过人工智能生成的图像,例如这四只柯基犬。

也许你还见过人工智能生成的声音,比如这些柯基犬吠叫的声音:
现在,当我说“它们是同一件事”时,你可能会感到困惑。
2024年5月,密歇根大学的三位研究人员发布了一篇题为《声音图像:在单一画布上创作图像和声音》的论文。
在这篇文章中,我将解释:
- 什么是生成“声音图像”,以及这与人类之前的工作有什么联系
- 该模型在技术层面的工作原理,并以易于理解的方式呈现
- 为什么这篇论文挑战了我们对AI能做什么以及应该做什么的理解
什么是“声音图像”?
要回答这个问题,我们需要理解两个术语:
- 波形
- 声谱图
在现实世界中,声音是由振动物体产生的声波(气压随时间的变化)产生的。当声音通过麦克风捕捉或由数字合成器生成时,我们可以将这种声波表示为波形:
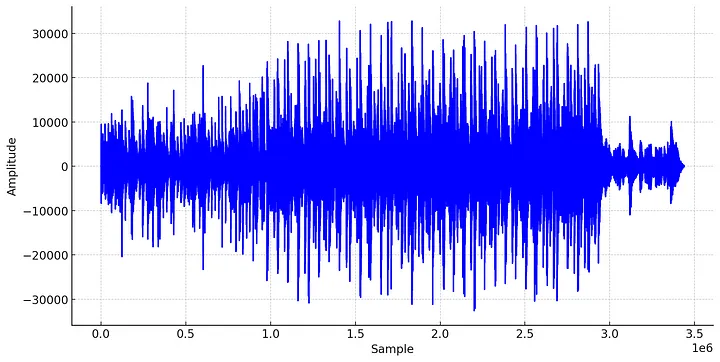
波形在录制和播放音频时非常有用,但通常在音乐分析或音频数据的机器学习中不常使用。取而代之的是更具信息量的信号表示——声谱图。

声谱图告诉我们在声音中哪些频率在不同时间点上更为突出。然而,对于本文而言,关键要注意的是,声谱图本质上是一个图像。至此,我们完成了完整的理解。
当生成上面提到的柯基犬的声音和图像时,AI会创建一种声音,当该声音被转换为声谱图时,它看起来就像一只柯基犬。
这意味着该AI的输出同时是声音和图像。
AI如何生成这些艺术作品?
即使你现在理解了什么是“声音图像”,你可能仍然会好奇这如何成为可能。AI如何知道哪种声音会生成所需的图像?毕竟,柯基犬声音的波形看起来与柯基犬毫无相似之处。
首先,我们需要了解一个基础概念:扩散模型。扩散模型是像DALL-E 3或Midjourney等图像生成模型背后的技术。本质上,扩散模型将用户的提示编码为一个数学表示(称为嵌入),然后通过从随机噪声逐步生成所需的输出图像。
以下是使用扩散模型创建图像的工作流程:
- 使用人工神经网络将提示编码为嵌入(即一组数字)。
- 使用白噪声(高斯噪声)初始化图像。
- 逐步对图像进行去噪。基于提示嵌入,扩散模型确定一个最佳的、微小的去噪步骤,使图像逐渐接近提示描述。我们可以称这个步骤为去噪指令。
- 重复去噪步骤,直到生成无噪声的高质量图像。

为了生成“声音图像”,研究人员巧妙地将两个扩散模型结合在一起。一个扩散模型是文本到图像的模型(Stable Diffusion),另一个是文本到声谱图的模型(Auffusion)。每个模型都会接收自己的提示,并将其编码为嵌入,决定各自的去噪指令。
然而,多个不同的去噪指令会带来问题,因为模型需要决定如何对图像进行去噪。论文中,作者通过平均两个提示的去噪指令来解决这个问题,从而有效地引导模型同时优化两个提示。这样,模型能够在生成过程中同时考虑图像和声音的要求,最终生成既能表现为图像又能表现为声音的作品。

从更高层次来看,可以认为这种方法确保生成的图像同时能很好地反映图像和音频提示。这种方法的一个缺点是输出结果总是两者的混合体,因此并非每个从模型中生成的声音或图像都会看起来或听起来很完美。这种内在的权衡显著限制了模型的输出质量。
这篇论文如何挑战我们对AI的理解
AI只是模仿人类智能吗?
AI通常被定义为模仿人类智能的计算机系统(例如,IBM、TechTarget、Coursera的定义)。这种定义适用于销售预测、图像分类和文本生成等AI模型。然而,这一定义也隐含了一个限制,即计算机系统只有在执行人类历史上已经解决的任务时才能被称为AI。
在现实世界中,存在大量(可能是无限多)可以通过智能解决的问题。虽然人类智能已经破解了一些这些问题,但大多数仍然未解。其中一些未解问题是已知的(例如治愈癌症、量子计算、意识的本质),而其他问题仍然未知。如果你的目标是解决这些未解的问题,单纯模仿人类智能可能并不是最佳策略。
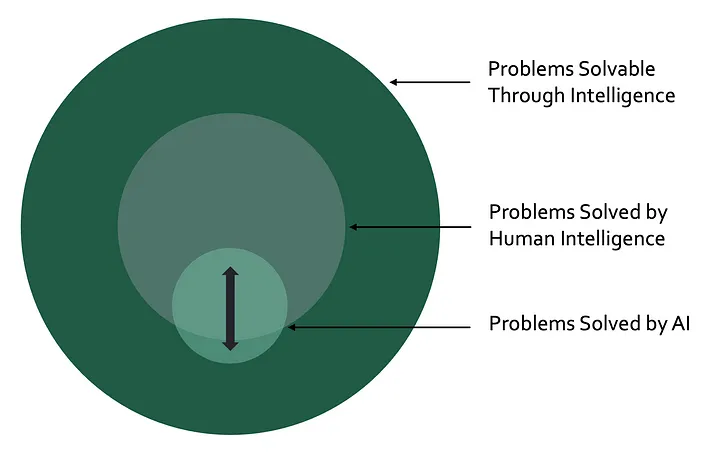
根据上述定义,一个无需模仿人类智能就发现癌症治疗方法的计算机系统不被视为AI,这显然是违背直觉且有害的。我并不打算引发关于“唯一定义”的争论,而是想强调,AI不仅仅是人类智能的自动化工具,它还有潜力解决我们甚至不知道存在的问题。
人类智能能生成声谱图艺术吗?
在Mixmag的一篇文章中,Becky Buckle探讨了“艺术家们将视觉效果隐藏在音乐波形中的历史”。一个令人印象深刻的人类声谱图艺术例子是英国音乐家Aphex Twin的歌曲《∆Mᵢ⁻¹=−α ∑ Dᵢ[η][ ∑ Fjᵢ[η−1]+Fextᵢ [η⁻¹]]》。这首歌展示了人类如何通过波形创造出独特的视觉艺术。
这个例子说明了人类艺术家如何运用智能来创造声谱图艺术,但这与AI生成的“声音图像”存在本质不同。AI的能力不仅在于模仿人类的艺术表现形式,还在于探索和创造新的艺术形式,这些形式可能超越人类现有的创作能力。通过AI,我们有机会发现和体验那些我们以前无法想象的艺术表现手法和形式。

另一个例子是加拿大音乐家Venetian Snares的专辑《Songs about my Cats》中的曲目《Look》。
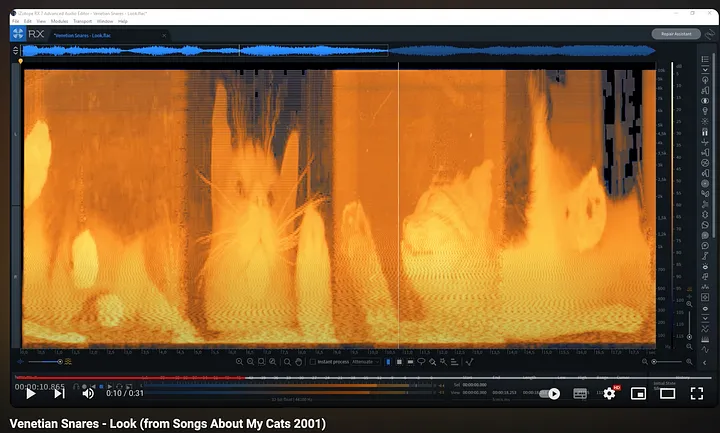
虽然以上两个例子显示了人类可以将图像编码到波形中,但与“声音图像”的能力相比,存在明显的差异。
“声音图像”与人类声谱图艺术有何不同?
如果你聆听上述人类声谱图艺术的例子,你会注意到它们听起来像噪音。对于外星人面孔来说,这可能是一种合适的音乐背景。然而,在聆听“猫”的例子时,声音和声谱图图像之间似乎没有任何有意的关系。人类作曲家能够生成在转换为声谱图时看起来像某种东西的波形,但据我所知,没有人能够根据预定标准,生成声音和图像匹配的例子。
“声音图像”可以生成听起来像猫、看起来也像猫的音频。它还可以生成听起来像飞船、看起来却像海豚的音频。它能够在音频信号的声音和图像表示之间建立有意的关联。在这方面,AI展现了非人类智能的能力。
“声音图像”没有实际用途,这正是它的美丽之处
近年来,AI更多地被描绘为一种生产力工具,可以通过自动化提升经济产出。虽然大多数人会同意这种观点在某种程度上是非常理想的,但也有些人对这种未来的前景感到威胁。毕竟,如果AI不断取代人类的工作,它最终可能会取代我们热爱的工作。如此一来,我们的生活可能会变得更有生产力,但也可能变得不那么有意义。
“声音图像”的独特之处在于它并非为生产力或实用性而生,而是纯粹为探索和艺术而存在。这种AI展示了非人类智能的创作潜力,不仅打破了我们对AI的传统认知,也拓宽了我们对未来艺术形式的想象空间。在这个意义上,“声音图像”是一种美丽的探索,即使它没有明确的应用场景,它仍然展现了AI的无限可能性。
“声音图像”与这种以经济为导向的观点形成了鲜明对比,是美丽AI艺术的一个典型例子。这项工作并非出于经济问题的驱动,而是由好奇心和创造力所推动。尽管我们不应轻易否定未来的可能性,但这项技术不太可能在经济上有实际的应用场景。
在我与人们讨论AI的过程中,艺术家往往对AI持最消极的态度。这一点也得到了德国GEMA最近一项研究的支持,研究显示,超过60%的音乐人“认为AI的风险超过其潜在的机会”,只有11%“认为机会大于风险”。
像这篇论文一样的作品有助于艺术家们理解,AI有潜力为世界带来更多美丽的艺术,而这并不一定要以牺牲人类创作者为代价。
展望:AI在艺术中的其他创造性用途
“声音图像”并不是AI在创造美丽艺术方面的第一个用例。在本节中,我想展示一些其他的AI艺术创作方式,希望能为您带来启发,并让您对AI有不同的看法。
艺术修复

AI帮助修复艺术作品,通过精确修复受损的部分,确保历史作品能够保存更长时间。这种技术与创意的结合,使我们的艺术遗产得以为后代保存。了解更多。
让绘画“活”起来
AI可以为照片添加动画效果,创造出具有自然动作和同步口型的逼真视频。它可以让历史人物或艺术作品(如蒙娜丽莎)动起来,甚至开口说话(或说唱)。尽管在深度伪造的背景下,这项技术具有一定的危险性,但将其应用于历史肖像时,却能创造出有趣和/或富有意义的艺术作品。了解更多。
将单声道录音转化为立体声
AI有潜力通过将旧录音的单声道混音转换为立体声混音来增强其效果。尽管已有传统的算法方法来实现这一点,但AI有望使人工立体声混音听起来越来越逼真。
结论
声音图像,利用先进的AI训练技术实现了一个纯粹的艺术结果,创造了一种全新的视听艺术形式。最令人着迷的是,这种艺术形式在当今超越了人类的能力范围。我们可以从这篇论文中了解到,AI不仅仅是一组模仿人类行为的自动化工具。相反,AI可以通过增强现有的艺术或创造全新的作品和艺术形式来丰富我们的审美体验。我们才刚刚开始看到AI革命的初步迹象,我迫不及待地想参与并体验它带来的(艺术)影响。