ETRI的研究人员公布了一项技术,该技术将生成人工智能和视觉智能相结合,可以在2秒内从文本输入中创建图像,推动了超快生成视觉智能领域的发展。
电子和电信研究所(ETRI)宣布向公众发布五种型号。其中包括三个“KOALA”模型,它从文本输入中生成图像的速度是现有方法的五倍,以及两个会话视觉语言模型“Ko-LLaVA”,它可以用图像或视频进行问答。
“KOALA”模型使用知识蒸馏技术将公共SW模型的参数从25.6B(25.6亿)显著降低到700M(7亿)。大量的参数通常意味着更多的计算,导致更长的处理时间和增加的操作成本。研究人员将模型尺寸缩小了三分之一,并将高分辨率图像的生成速度提高到以前的两倍,与DALL-E 3相比提高了五倍。
ETRI成功地大幅缩小了该型号的尺寸(1.7B(大)、1B(基本)、700M(小)),并将生成速度提高到约2秒,使其能够在国内外文本到图像生成竞争激烈的环境中,在只有8GB内存的低成本GPU上运行。
ETRI内部开发的三款“KOALA”模型已在HuggingFace环境中发布。
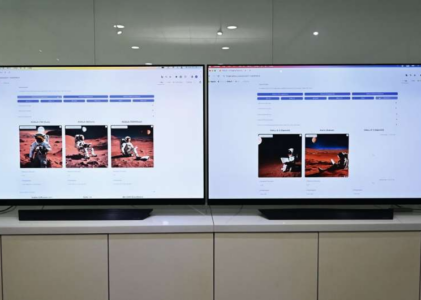
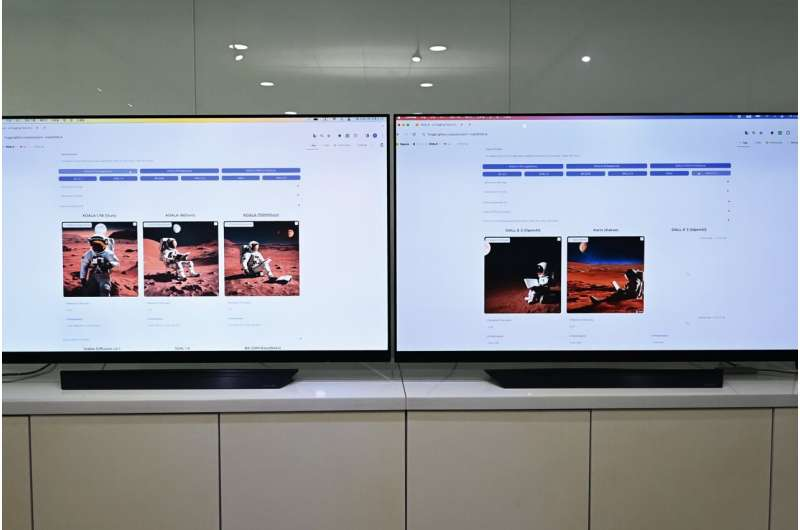
在实践中,当研究团队输入句子“宇航员在火星月球下看书的照片”时,ETRI开发的KOALA 700M模型仅用1.6秒就创建了图像,明显快于Kakao Brain的Kallo(3.8秒)、OpenAI的DALL-E 2(12.3秒)和DALL-E 3(13.7秒)。
ETRI还推出了一个网站,用户可以直接比较和体验总共9种模型,包括两种公开的稳定扩散模型,BK-SDM、Karlo、DALL-E 2、DALL-E3和三种KOALA模型。
此外,研究团队还推出了会话视觉语言模型“Ko LLaVA”,该模型为ChatGPT等会话人工智能添加了视觉智能。该模型可以检索图像或视频,并用韩语回答有关它们的问题。
“LLaVA”模型是在威斯康星大学麦迪逊分校和ETRI的一个国际联合研究项目中开发的,该项目在著名的人工智能会议NeurIPS’23上发表,并利用了具有GPT-4级别图像解释能力的开源LLaVA(大型语言和视觉助手)。
研究人员正在进行扩展研究,以提高对韩语的理解,并引入基于LLaVA模型的前所未有的视频解释能力,该模型正在成为包括图像在内的多模式模型的替代品。
此外,ETRI预先发布了自己的基于韩语的紧凑语言理解生成模型(KEByT5)。已发布的模型(330M(小)、580M(基本)和1.23B(大))应用了能够处理新词和未经训练的单词的无标记技术。训练速度提高2.7倍以上,推理速度提高1.4倍以上。
研究团队预计,生成人工智能市场将从以文本为中心的生成模型逐渐转向多模式生成模型,在模型规模的竞争格局中,模型将朝着更小、更高效的方向发展。