

研究人员展示了一种使用Stable Diffusion和新的混合3D表示的方法,用于创建和编辑3D化身。
人工智能领域的新兴技术正在使虚拟人物的创建变得越来越逼真。来自马克斯·普朗克智能系统研究所等机构的两项最新研究项目现在展示了一种方法,可以将化身的不同组成部分(如身体、服装和头发)分离出来,以进行编辑操作,甚至生成文本到化身的功能。
分离身体、服装和头发有助于生成
在一篇名为“DELTA:使用混合3D表示学习分离化身”的论文中,研究人员提出了一种创建化身的方法,其中包括独立的身体和服装/头发层。他们的关键想法是为不同的组成部分使用不同的3D表示:身体采用显式的基于网格的模型建模,而服装和头发则用可以捕捉复杂形状和外观的神经辐射场(NeRF)表示。
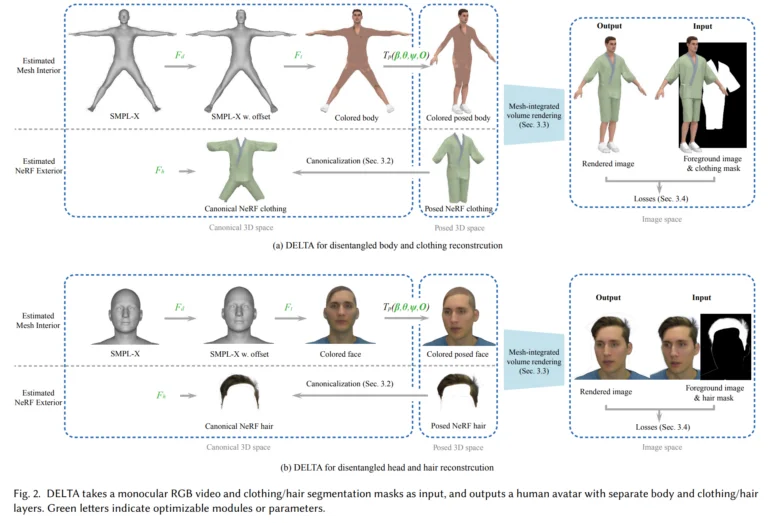
要创建一个新的化身,DELTA只需要单眼RGB视频作为输入。一旦训练完成,该化身就可以实现虚拟试衣或形状编辑等应用。服装和头发可以在不同的身体形状之间无缝传输。
文本转头像方法 TECA 使用 DELTA
在”TECA: 文本引导的组合3D化身生成和编辑”中,研究人员着手解决仅从文本描述创建化身的任务。为此,他们使用了Stable Diffusion和在DELTA中开发的混合3D表示。
系统首先使用Stable Diffusion从文本描述生成一个脸部图像,作为3D几何的参考,然后迭代地为网格添加纹理。然后,它使用CLIP分割引导的NeRF依次添加头发、衣服和其他元素。
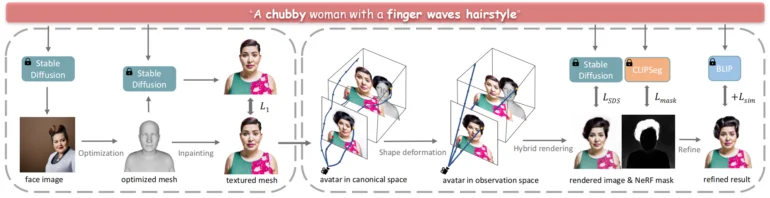
这种方法生成的组合化身在质量上明显优于以前的文本到化身技术。研究人员表示,关键在于解开各个部分的联系,从而实现了强大的化身之间属性转移的编辑。