
生成式人工智能(GenAI)的淘金热潮已经蓬勃发展。现在,GenAI能够创造出在很多情况下难以与人类创作区分的内容,包括文字、图像、视频和音频。这种技术已经迅速影响到了人类创造力的多个领域,如写作、视觉设计、编码、营销、游戏制作、音乐创作和产品设计等。而且,随着创意服务被整合到产品中,如Microsoft Office 365、Slack、Discord、Salesforce Cloud和Gmail,GenAI将在不知不觉中提高数十亿人的工作效率。我们很快都会使用GenAI来创建各种工作和项目的初稿。
那么,谁将从GenAI中获利呢?让我们深入探讨一下。

实际上,在这场淘金热潮中,有五个“层次”可以捕获潜在的价值:
- 基础设施 – 提供芯片和云基础设施的公司将运行庞大的GenAI计算机模型。这些基础设施是支撑整个GenAI生态系统的关键。
- 基础模型 – 那些构建大型文本、图像、音频和其他模型以生成创意输出的公司。这些基础模型为GenAI的发展提供了坚实的基础。
- 应用程序 – 大型和小型公司正在开发应用程序,这些应用程序将被消费者、企业和政府用于创意任务。这包括创造性的工具和娱乐应用等。
- 行业和组织 – 作为其创意活动的一部分,将从GenAI应用程序、工具和平台中提取价值的行业和组织。这包括广告、媒体、教育、医疗保健等各个领域。
- 国家 – 将在国内外创建、出口和部署GenAI技术的国家。这包括国际合作和国际市场。不同国家的政府和企业都将在这一技术的全球传播中发挥重要作用。
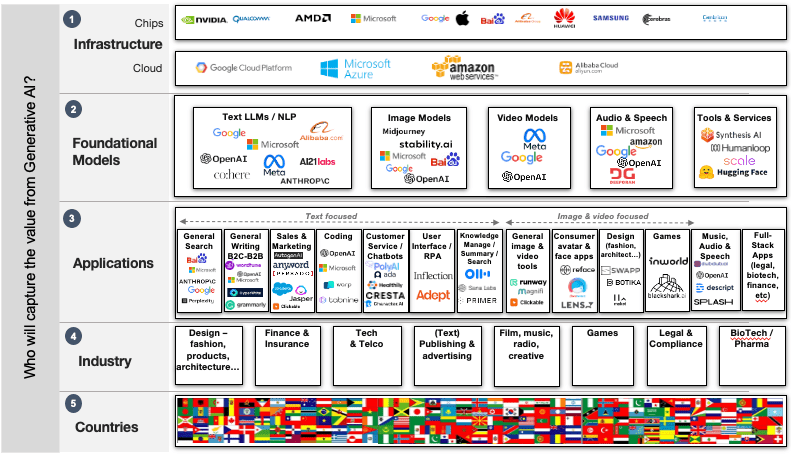
在每个层面上,谁将成为赢家呢?
GenAI基础设施
大型科技公司已经在GenAI基础设施领域占据主导地位,拥有强大的云服务和硬件芯片。这些公司包括亚马逊、谷歌、微软等。它们拥有庞大的数据中心和先进的云计算基础设施,使它们能够提供高性能的计算和存储资源,支持GenAI的发展。

在美国云市场,微软和谷歌占据了有利地位,而在中国,百度和阿里巴巴处于领先地位。它们庞大的超级计算机云基础设施经过精心设计,可以运行GenAI复杂、昂贵、大规模的文本、视觉和音频基础模型。已经有许多开发者使用它们的云AI API服务和工具来构建应用程序,预计随着创业者纷纷投身几乎无限的GenAI用例,这一趋势将加速发展。
至于亚马逊,他们在基础模型方面一直较为沉默,因此一个重要的问题是他们将如何应对。
GenAI需要大量的计算能力来生成创意输出。OpenAI的首席执行官Sam Altman表示:“在某个时候,我们将不得不在一定程度上将其商业化;计算成本令人瞠目结舌。”据传闻,OpenAI的GPT-3训练仅耗资1200万美元的能源费用。
因此,毫不奇怪OpenAI在2023年初从微软获得了100亿美元的投资,其中大部分将以访问Microsoft Azure的超级计算基础设施的形式提供。芯片制造商们对于超级计算机算力的需求垂涎三尺。拥有超过五千亿美元市值的英伟达(NASDAQ: NVDA)股价从2018年的60美元上升到了2023年初的240美元。大型科技公司也正在投资于他们自己的AI优化芯片。最近美国对向中国出口先进AI芯片实施了出口禁令,这将加速中国政府的补贴和国内半导体产业的投资(同时引发地缘政治紧张局势)。考虑到需要大量的投资,这个领域的赢家将是那些受到大公司支持的实体或公司。
基础模型
大型科技公司在开发GenAI基础模型方面具有竞争优势,其规模和范围为它们提供了巨大的计算资源。
这些模型是在大量数据上训练的,利用了大型科技公司的庞大计算资源。例如,OpenAI的GPT-3文本模型,也就是大型语言模型(LLM),是在约45TB的文本数据上训练的,代表了从大部分英语互联网中“搜集”来的约5000亿字的数据。同样,OpenAI的Dall-E-2文本到图像模型是在6.5亿图像-字幕对上进行的训练。大型科技公司不希望失去在云服务领域的领导地位,因为未来数十亿终端用户使用这些基础模型将产生巨大的收入流。
微软已经与OpenAI合作,谷歌最近推出了Bard语言聊天机器人,这与它的Imagen模型用于从输入文本创建逼真图像相辅相成。中国的大型科技公司也在积极进展。阿里巴巴正在测试一项内部聊天服务。百度已经提供了ERNIE-ViLG,一个文本到图像参数模型,并正在测试一项新的聊天机器人服务。大型科技公司的规模赋予它们多个优势,这些优势将令初创企业难以复制。

BigTech具备规模优势来解决基础模型的真实性、偏见和毒性问题
BigTech可能是唯一能够应对GenAI较为阴暗面的参与者。虽然GenAI仍处于初级阶段,但基础模型的问题已经显现出来。这些问题包括真实性(GenAI生成明显错误的内容)、偏见(对特定群体的偏见)和毒性(例如,种族主义、性别歧视或仇恨言论)。在2023年初,Alphabet的市值蒸发了1000亿美元,因为金融市场对Google的Bard聊天机器人服务提供的错误和冒犯性回答感到恐慌。微软有限发布的Bing聊天机器人也显示出一些令人不安的回答(甚至是种族主义),尽管其股价没有急剧下跌。还有一种新型的网络攻击称为提示注入,可以通过注入恶意指令来绕过防护措施。
开发这些基础模型的挑战将在于确保它们的输出既负责任又准确。基础模型不能简单地重复从互联网的各个角落抓取的带有偏见和毒性的内容。这些模型还具有幻觉性。这意味着它们可以自信地为可能事实不准确的问题提供构思良好且雄辩的答案。正如Character.AI的联合创始人Noam Shazeer在《纽约时报》中所说:
“…这些系统并非为真相而设计。它们是为了具有合理对话而设计的。”
BigTech不能承受基础模型失败可能带来的声誉、财务和战略风险。他们正在建立监管监督系统,其中包括防护措施和模型调整。为了赢得用户的信任并满足可能的监管要求,BigTech需要为模型的透明度、可解释性和引用来源工程化解决方案。来自人类反馈的强化学习(RLFH)将需要大量人员来审查和评价模型对问题的答案。这些都不是简单的大规模问题解决方案。再次强调,由于其资本、工程人才、数据集和数十亿用户的人类反馈循环规模,BigTech具备有利地位。
BigTech模型并非在所有情况下都适用
尽管规模庞大,但BigTech将无法控制整个基础模型热潮。他们的模型在水平方面广泛适用,适合回答任何可以想象的消费者问题,但并不总是适用于企业垂直任务的需求。为什么呢?BigTech的水平模型(1)在专业任务上通常表现不佳,(2)经常不保护企业专有数据,(3)未经培训的非英语语言,(4)缺乏透明度和可解释性,(5)不适合在边缘设备和内部使用,(6)在云中运行可能成本高昂,(7)会让公司对BigTech产生依赖。
极少数融资极其充足的初创公司提供了BigTech基础模型的替代方案
BigTech基础模型并不适合每个人。这为一些融资极其充足的初创公司提供了空间,它们已经筹集了数亿甚至数十亿美元的资金。
- 于2021年创立的Anthropic专注于更可靠、可解释和可控的LLM,已经筹集了超过10亿美元的资金,最近一轮投资来自谷歌,金额为3亿美元。
- AI21labs为其Jurassic-1文本模型筹集了1.19亿美元的资金。拥有1780亿参数的Jurassic-1在规模上与GPT-3相似。
- Cohere为LLM和自然语言处理(NLP)作为服务筹集了1.65亿美元。
- BLOOM是一个私营的、公共研究的LLM项目,由私营部门的Hugging Face和欧洲研究机构支持,旨在创建一个具有1760亿参数的开源LLM。它已经在46种人类语言上进行了培训,其中包括大多数LLM中未充分涵盖的20种非洲语言。
- 英国的Stability AI最近筹集了1亿美元,估值超过10亿美元,用于其开源的图像生成服务Stable Diffusion。
BigTech意识到他们的模型存在局限性,特别是微软最近宣布企业将能够“微调”其模型,而无需担心会共享专有数据以构建更好的模型。
然而,这些措施不会让每个人都满意。德国初创公司Adelph Alpha已经筹集了3100万美元,正在解决企业对BigTech基础模型的担忧,推出了自己的“欧洲”中心模型。但尚不清楚它们是否能够在规模上竞争。
BigTech将赢得水平基础模型的竞赛,为一些高度资本化的初创公司提供了空间。也许开源模型如BLOOM和Stable Diffusion将获得规模,或至少找到一个小众市场。一如往常,将有工具和服务提供商从与这些基础模型一起工作变得更加容易中获利。但总的来说:
BigTech之所以在基础模型上市场占据优势,是因为他们能够有效地免费提供基础模型,因为他们将从其基础云服务中获得大部分利润。
生成AI应用程序
虽然BigTech将赢得GenAI黄金热潮的“镐和铲”,但应用层面则更加公平。现有的企业软件公司、全堆栈初创公司以及这些基础模型的启用者成千上万的初创公司将提供新的GenAI应用程序。
传统的企业软件公司,如Salesforce和Microsoft,将有机或通过收购为数十亿用户提供GenAI能力。微软还将其GenAI聊天机器人服务整合到其必应搜索应用程序中,直接挑战了谷歌的搜索霸主地位。
少数一些资金充足的初创公司将提供专门的“全堆栈”应用程序。在具有专门数据、序列和计算要求的领域,这些公司将开发自己的基础模型。例如,GenAI可以通过构建自己的模型和应用程序,彻底改变药物发现和材料科学。投资者将被这些初创公司所吸引,因为它们可能提供可观的财务回报以及强大的竞争防御能力。
例如,Adept AI已经筹集了6500万美元,致力于基于LLM的自然语言界面的下一代机器人流程自动化(RPA)的开发。Inflection.ai正在隐身模式下进行类似的工作。Character.AI是一款聊天机器人,采用角色的声音和知识,已经筹集了2亿美元至2.5亿美元左右的估值,用于支持实时代理企业应用程序的专业LLM的全堆栈实现。
GenAI的采用速度将非常快。如果一个由AI生成的市场宣传稿的初稿不完美,那么简单地进行编辑即可。ChatGPT是历史上增长最快的消费者应用程序,仅在推出后的两个多月内就拥有了超过1亿的月活跃用户。这意味着对几乎无限数量的GenAI创意应用的争夺将激烈而迅速。

将有适用于各种用例的“Copilot” GenAI应用程序
将GenAI投入使用将会看到全球的消费者、企业和组织使用由建立在这些基础模型之上的初创公司提供的应用程序。许多GenAI初创公司将采用“Copilot for X”业务模型,以协助用户执行“创意”任务,如写作或编码,以及重复性任务,如数据输入或表单填写。以下是一些竞争在各个垂直领域赚钱的初创公司。
- 通用文本写作初创公司正在协助用户实时处理日常写作任务,如电子邮件撰写、文档创建和文本表单填写。AI21labs的Wordtune将“将您的文本重新编写,就像是专业的文案撰稿人”。写作助手之王是Grammarly,已经筹集了超过4亿美元。写作初创公司的名单很长,包括Lex、HyperWrite、Compose AI和Rytr等。
- 销售和营销初创公司包括已筹集了1.45亿美元的庞大Jasper.ai。Anyword已筹集了超过4500万美元,提供“高转化的文本内容用于销售”。Persado筹集了超过6600万美元,用于语言生成,“96%的时间表现优于您的最佳文案”。初创公司越来越专注于特定任务,如编写产品营销描述。
- 图像生成初创公司由Open AI的DALL-E-2、Stability AI的Stable Diffusion和Midjourney的文本到图像基础模型提供支持。初创公司包括Art Breeder,帮助用户创建拼贴图像。
- 消费者面部和头像初创公司包括Lightricks的Facetune应用程序,协助创建“完美”的Instagram图像。Lightricks已经筹集了3.5亿美元。用户可以使用非常受欢迎的Lensa AI应用程序创建个体“魔法头像”。Reface允许用户将他们的脸部置换到不同的场景中,已经筹集了550万美元。
- 产品设计初创公司包括Botika,该公司正在使用高质量服装在各种环境中为模特创建超逼真的图像,以“重新发明时尚摄影”。Maket可帮助从文本提示中生成建筑方案,而不是几个月。Tailorbird加快了房主想要翻新的户型平面图的创建。Swapp已筹集了700万美元,以帮助自动化项目的施工文档。TestFit已筹集了2200万美元,用于房地产设计。
- 以视频为重点的初创公司提供视频创意、生成、编辑和工作协作工具。Runway是融资最多的初创公司,拥有近1亿美元的资金。Magnifi已经筹集了超过6000万美元用于视频编辑,而InVideo已筹集了超过5300万美元。一些初创公司,包括已筹集了2600万美元的Hour One,提供文本到视频服务。总部位于伦敦的Synthesia已筹集了超过6700万美元,用于其头像视频创建平台。总体而言,NFX正在追踪54家为生成式视频初创公司筹集了总计5亿美元的公司。
- 音频GenAI初创公司包括音乐创作公司Soundraw、Boomy和Aiva。Splash已筹集了2300万美元,允许用户创建原创音乐并为任何旋律唱歌。DupDub已经筹集了超过2.5亿美元用于配音服务,并声称拥有100万用户。Descript已筹集了超过1亿美元,为音频转录、播客、屏幕录制、音频和视频编辑提供语音克隆。Deepgram的语音到文本服务与BigTech和OpenAI的Whisper竞争,并已获得超过8700万美元的资金支持。
- 游戏生成初创公司希望节省游戏制作工作室数亿美元的制作成本。Masterpiece Studio已筹集了600万美元,用于创建2D到3D模型。Replica已筹集了500万美元,专注于游戏、电影和元宇宙中的AI声音演员。Latitude/AI Dungeon是一家筹集了400万美元用于基于文本的游戏生成的游戏工作室。VoiceMod已筹集超过700万美元,提供游戏中的实时语音变换,如Fortnite和Skype等应用。Ponzu是一个用于创建3D表面纹理的初创公司,Charisma AI则是一个用于创建虚拟角色的初创公司。Inworld已筹集了7000万美元,用于其面向“沉浸式现实、虚拟角色和元宇宙空间创建”的AI开发者平台。总体而言,A16Z目前正在跟踪50多家游戏行业的初创公司。
- 聊天机器人和对话AI初创公司包括垂直领域的健康症状检查器ada,已筹集了1.9亿美元,以及英国的Healthily,已筹集了约7000万美元。鉴于AI可以每年为呼叫中心企业节省800亿美元,初创公司正在筹集大笔资金。Cresta AI已经筹集了超过1.5亿美元,总部位于伦敦的PolyAI已经筹集了6800万美元,用于其“超级人工智能语音助手”。
- 编码共同合作初创公司正在跟随微软的GitHub Copilot的先例,后者声称可以自动生成高达40%的代码。Warp是一家将自然语言转化为计算机命令的公司,已筹集了7000万美元。Tabnine已筹集了3000万美元。
- 知识管理、摘要和企业搜索初创公司包括Primer AI,已筹集了1.68亿美元,以及Otter,已筹集了6300万美元。总部位于斯德哥尔摩的Sana Labs已筹集了5460万美元,以促进组织内信息的发现、共享和再利用。
那么哪些初创公司会获胜?
流入GenAI应用初创公司的资本不乏。在垂直领域,全堆栈初创公司将筹集大笔资金,其中将创建高度专业化的模型和应用程序,例如药物发现。在更广泛的B2B领域,竞争将同时涵盖水平和垂直,以Copilot业务模型为中心。一方面,水平初创公司将在各个行业提供服务,例如Jasper的销售和营销助手。另一方面,初创公司越来越专注于按行业、功能和任务垂直领域。
获胜者将通过实施以下方法来实现规模和竞争优势:
- 强大的投资回报率——对于他们的用例以及快速证明价值的时间来说。
- 专有和定制的基础模型——使用本地化、专业化和专有公司数据对特定受众进行“微调”。
- 工作流程——证明可用性并深度集成到客户流程中,一旦安装就难以删除。
- 反馈循环——从人类反馈的强化学习(RLFH),例如,以改进模型与用户意图的一致性。
- 动能效应——通过“微调”通过更多的RLFH和其他反馈,提高模型性能,使用更多,因此动力增长。
由于大部分知识产权属于基础模型,因此规模是游戏的关键。那些能够快速建立品牌并吸引大量用户和客户以启动动能的初创公司将成为该领域的领先者。
在B2C GenAI消费者领域,速度快、大规模用户获取预算的水平玩家很可能会赢得竞争。
总部位于英国的AutogenAI就是一个很好的例子,它是一家B2B初创公司,已经为获胜提供了良好的定位。他们花了两年时间开发了一款帮助企业节省时间、金钱并提高投标、投标和提案质量的应用程序。他们通过使用公司网站内容、赢得和输掉的销售投标、营销文案和年度报告的示例来“微调”OpenAI LLM。他们还提供了一个人机监督用户界面,以协助审查生成的内容和事实的来源和准确性。这还提供了一个关键的人类强化学习循环,随着使用量的增加,用户越来越多地使用他们的应用程序作为下一代知识管理和搜索工具,使其更具粘性。
一些GenAI初创公司将被收购,并成为更大型企业和消费者应用程序的功能。例如,拥有数百万用户的大型社交媒体公司将收购最新的面部和头像创建初创公司。现有的图形设计软件公司将收购最有前景的图像和视频编辑初创公司。例如,微软现在正在将GenAI“Microsoft Dynamics 365 Copilot”本地化为其CRM和ERP应用程序的一部分。
简而言之,如果创业公司能够迅速建立规模和Copilot用例的动力,一些幸运和勇敢的初创公司将会获得巨大的利润。同样,一些全堆栈初创公司将在专业化用例如药物发现中蓬勃发展。由于筹集了大笔资金、制服了市场并且人们、企业和政府迅速采纳了创新,美国的初创公司将占主导地位。但是,大多数初创公司将空手而归,为这场淘金热的提供者的挖掘和铲子贡献了利润——主要是美国的BigTech。