随着近日在Replicate上发布的Stable Diffusion XL微调版本,以及正值Stable Diffusion推出一周年纪念日,现在似乎是一个绝佳的机会,让我们退后一步,反思过去几年文本至图像的AI是如何取得进步的。
我们见证了AI生成的图像从一堆难以理解的眼球和噪音,逐渐发展为高质量的艺术图像,有时几乎难以与画家的笔触或详细的插图渲染区分开来。
在这里,我们将迅速回顾文本至图像AI的演进,以了解过去几年取得的进步,从早期的 GAN experiments到最新的扩散模型。
前言
为了庆祝Stable Diffusion推出一周年,已经将免费的文本至图像AI创作工具更新至最新的Stable Diffusion XL 1.0模型。
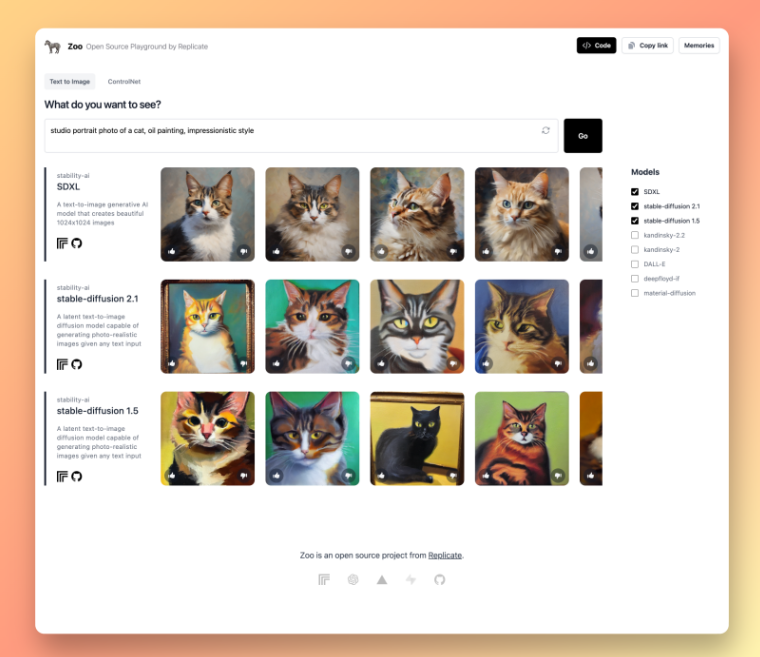
Zoo是一个开源网络应用,用于比较文本至图像生成模型。Zoo允许您将各种图像生成模型并排比较,因此,您可以通过同时比较多个模型中的相同prompt,将Stable Diffusion和其他文本至图像AI模型如何随着时间而改进进行可视化。Zoo包括Stable Diffusion 1.5, Stable Diffusion 2.1, Stable Diffusion XL 1.0, Kandinski 2.2, DALL·E 2, Deepfloyd IF, 以及 Material Diffusion。
目录
以下是本文将展示的模型列表。点击下面的任一标题,跳转到相应的部分。
- CLIP + DALL·E
- Advadnoun的DeepDaze
- Advadnoun的The BigSleep
- DALL·E 2
- DALL·E Mini
- Pixray
- VQGAN+CLIP
- Stable Diffusion 1
- Stable Diffusion 2
- Stable Diffusion XL (SDXL)
- Fine-tuning
CLIP + DALL·E
图文生成AI领域的发展在2021年1月开始迅速崛起,正是在那时,OpenAI发布了他们的CLIP模型。
CLIP是OpenAI推出的一个开源模型,它基于从网络收集的带字幕图像进行训练,能够将图像和文本都投影到同一个嵌入空间中进行分类。这意味着它对于给定图像中发生的事情有着语义理解。例如,如果您向CLIP提供一张香蕉的照片,它在嵌入空间中会与“黄色的香蕉”文本紧密相关。
图像和文本的这种多模态理解是文本至图像AI的重要基础要素,因为它可以用来引导文本至图像AI生成的结果,使其看起来与给定的文本提示相符。
OpenAI还发布了一篇详细介绍他们如何利用CLIP构建文本至图像模型DALL·E的论文。
虽然DALL·E从未完全开源,但该论文和方法激发了一些开源实现,这些实现最终塑造了我们所知的图文生成AI领域。
Advadnoun的DeepDaze
在DALL·E论文发布几天后的2021年1月,advadnoun发布了第一个开源的文本至图像AI实验。
网友@advadnoun分享了一个名为“深度黎明(Deep Daze)”的Colab笔记本。它结合了OpenAI的CLIP模型和SIREN模型,以创建几乎可辨识的图像。可在下面的图像中看到,这些图像初步呈现出与prompt的相似之处,但所有图像都非常抽象,从未趋于现实主义或可辨认的主题。
以下是使用DeepDaze生成的一些初始图像。比较有趣的是日落中的杨树(poplars at sunset),它几乎看起来像是一幅抽象的印象派绘画作品。




Advadnoun的 The BigSleep
大约一周后,网友@advadnoun分享了另一个名为“The BigSleep”的Colab笔记本。这个新的笔记本展示了CLIP模型与BigGAN模型的结合。
The BigSleep代表了朝着创建可辨识场景的明显改进,但图像仍然经常难以理解,充满了奇怪的伪影和错误。
最喜欢这些图像中的一幅是色彩鲜艳的场景(A scene with vibrant colors)——云朵是逼真的,而且这些充满活力的颜色看起来就像秋季的叶子。




DALL·E 2
到了2021年4月,整个领域开始转向扩散模型。
OpenAI宣布推出了DALL·E 2,并发表了一篇新论文详细介绍了他们的改进,演示了扩散模型如何提高了整体图像质量和一致性。DALL·E 2作为一个闭源产品发布,最初只向少数一些测试用户开放。
终于,梦想成真了!您可以输入类似“一幅猫戴着红帽子的画作(a painting of a cat wearing a red hat)”的prompt,它会为您生成一幅一只戴着红帽子的猫的图像。🤯


DALL·E Mini
接下来于2021年7月发布的另一个受欢迎的文本至图像AI模型是DALL·E Mini,这是由Boris Dayma等人开发的一个开源的文本至图像模型。
Boris发表了一篇精彩的深度解析,详细介绍了他们是如何将各种模型(包括VQGAN、CLIP和Bert)结合起来,从文本提示中创建出可辨识的图像。
👉🏼 在Replicate上运行DALL·E Mini生成的图像:




Pixray
Pixray是Replicate历史上重要的图像生成模型。在2022年初,Pixray是首个在Replicate上达到数万次运行的文本至图像模型。如今,它已经累计运行了130万次。
Dribnet是第一个正式要求大家构建API作为网络预测表单替代方案的Replicate用户。剩下的就成了历史! 😅
👉🏼 在Replicate上运行Pixray生成的图像:




VQGAN+CLIP
在2022年4月,用户@RiversHaveWings分享了一系列结合了VQGAN和CLIP的Colab笔记本。还有一篇论文,其中包含了一些有趣的示例,以及他们如何将VQGAN与CLIP相结合的详细描述。
VQGAN+CLIP在重新创造艺术的外观和感觉方面似乎是一个重大的进步。会注意到下面的图像开始与它们的prompt相似,艺术纹理,如刷笔的笔触和铅笔的痕迹,开始出现。VQGAN+CLIP被用来创建了第一批让人们惊讶的AI生成图像。
👉🏼 在Replicate上运行VQGAN+CLIP生成的图像:




Stable Diffusion 1
在2022年8月22日,Stable Diffusion 1.4首次亮相。模型权重以及所有的代码都被公开发布为开源。
在Hackernews上看到了一些示例,对一些人在评论中分享的结果感到印象深刻。当决定尝试一下时,感到非常怀疑。模型的权重在磁盘上只有4GB,能有多好呢?
不知何故设法在游戏电脑上启动了一切,电脑配备了一块带有8GB VRAM的NVIDIA RTX 2080 GPU。能够在本地电脑上生成任何想到的东西,简直难以置信。生成一张图片大约需要50秒,但无法相信这一切。那个晚上可能花了4个小时生成愚蠢的图片。
这是在2022年8月30日第一次使用Stable Diffusion生成。想想这甚至还不到一年,真是不可思议。

以下是使用Stable Diffusion1.4和1.5生成的一些其他图像。从VQGAN和DALL·E Mini到现在,回顾这些作品,仍然对其质量的提升感到惊讶,






Stable Diffusion 2
Stable Diffusion2于2022年10月首次发布,有点像是第二张尴尬的专辑。还不错,只是… 有些不同。
第2版有几个变化和改进,如negative prompt、使用OpenCLIP作为文本编码器、更大的图像输出等。
迁移到OpenClip导致与Stable Diffusion之前版本相比,图像输出和构图发生了显著的变化。对许多人来说,这感觉像是“破坏性的变更”。最显著的是,这次迁移导致许多艺术家的名称从文本编码器中被移除,直到今天,这使得一部分用户仍然更愿意使用1.5版本而不是2.1版本。
不能再像在Stable Diffusion v1.x中那样使用类似ARTIST_NAME_HERE的风格提示,从而获得特定风格化的结果。
新的OpenCLIP变化鼓励用户使用更具描述性的prompt,描述想要生成的图像细节,而不是复制整个风格。
以下是使用Stable Diffusion2.1生成的一些图像:




Stable Diffusion XL (SDXL)
这将我们带到了最新和最伟大的文本至图像AI模型,Stable Diffusion XL,在2023年7月26日发布。
SDXL提供了更高质量的图像,更少的伪影以及更一致的结果。SDXL支持修复、图像生成、细化、专家集成生成、微调等功能。
在使用了几个星期后,基础模型的结果惊人地好。可以亲自尝试一下。
以下是一些SDXL图像的示例:




这些图像令人惊叹,但似乎只是刚刚开始。在当前的开发速度下,开源社区在未来的几个月和几年内肯定会提供更好的模型、工具和工作流程。现在是一个令人兴奋的时刻,因为已经拥有了基本的工具和坚实的基础来构建。
展望未来,我们将在微调、构图控制和创意增强方面看到更多进展。这些东西在Stable Diffusion中已经存在,但只能想象它们会变得更好、更快、更易于使用。
Fine-tuning
Fine-tuning是将预训练的基础模型(如Stable Diffusion)进一步训练在特定数据集上的过程。在文本至图AI模型的背景下,这意味着可以训练Stable Diffusion生成您的狗的图像、您最喜欢的动漫角色,或者您最喜欢的艺术家的风格。当今一些流行的Fine-tuning包括DreamBooth、LoRA和Textual Inversion。
这就是开源模型在Midjourney或DALL·E 2等私有模型面前的优势所在;通过允许您对日常生活中的主题/对象进行训练和生成。
Replicate最近为SDXL发布了Fine-tuning。下面是狗狗Queso的微调模型的并排比较。每个图像都使用相同的prompt。左边是Stable Diffusion 2.1的Dreambooth,而右边是通过遵循上面提到的来微调的SDXL模型。


以下是一些精彩的作品:




展望未来
随着SDXL的发布,以及开源微调和ControlNet模型的持续发展,正逐渐接近创意自由和控制的乐土,您可以生成您想象得到的任何东西。





