


VideoControlNet通过扩散模型和ControlNet实现对AI生成视频的更多控制。
目前已经有几种扩展来对Stable Diffusion的图像合成实现更好的控制。其中最重要的一种是ControlNet。例如,它可以从输入图像中提取人的姿态或房间的结构,并将其作为图像合成的模板。
北京航空航天大学和香港大学的研究人员现在提出了VideoControlNet,这是一种将这一思想应用于视频合成的扩展。
尽管有些令人印象深刻的生成结果,如Runway的Gen-2,但基于扩散模型的视频合成仍受制于伪影并难以控制。另一方面,VideoControlNet使用提示信息和输入视频共同生成新的视频。这使得在保留原始视频的几何结构和时间结构的同时,可以替换背景、灯光或人物。
VideoControlNet基于视频编解码方法
VideoControlNet的灵感来源于视频编解码器减少视频序列中不必要的重复信息的方式。具体而言,该团队将第一帧定义为I帧,并将后续帧划分为不同的帧组(GOP),每个GOP的最后一帧定义为关键帧(P帧),其他帧定义为B帧。
视频的第一帧称为I帧,是使用扩散模型和ControlNet生成的。然后,基于前一帧的变化生成P帧,即I帧或其他P帧。该团队开发了一种称为运动引导的P帧生成(MgPG)的技术。当图像的部分被遮挡时,扩散模型会填充它们。
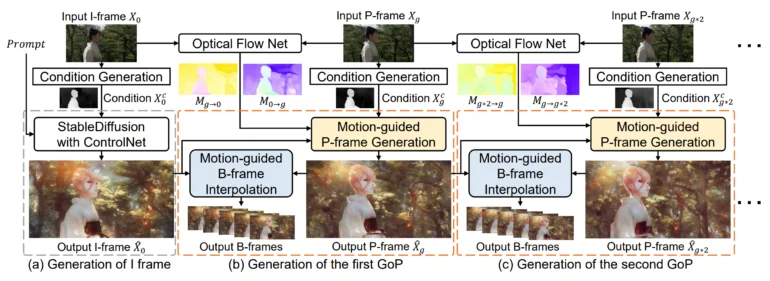
最后,使用该团队称为运动引导的B帧插值(MgBI)的方法生成所有剩余帧或B帧。这些B帧基于前后B帧的信息。
简而言之,VideoControlNet通过模拟视频编码的工作流程,实现对合成视频的结构、运动和细节的更细粒度控制,是一大创新。这为创作者提供了更多可能性去调整和优化AI生成的视频素材。期待这个有前景的技术不断完善,让视频内容生产变得更加高效和可控。
下一步目标是提高一致性
在实验中,该团队展示了VideoControlNet保留了其使用的扩散模型的生成能力,并通过使用运动信息成功将其扩展到视频。
该团队展示了样式迁移、前景和背景视频编辑的示例。接下来,该团队希望整合更多的学习网络来提高一致性。VideoControlNet项目页面上提供了更多示例和代码。
Style Transfer(风格迁移)


Foreground(前景)

Background(背景)

VideoControlNet为我们对AI生成视频内容的控制提供了新的维度。这项研究充分利用了视频编解码的思路,具有创新性。希望该团队可以继续改进一致性问题,使这一技术成为视频创作者的强大新工具。掌握内容生成将是所有创作者需要重点发展的未来核心竞争力。