

大规模预训练后进行任务特定微调的语言建模方法取得了显著成功,并已成为标准实践。同样,计算机视觉方法也逐渐采用大规模数据进行预训练。大型数据集的出现,如LAION5B、Instagram-3.5B、JFT-300M、LVD142M、Visual Genome和YFCC100M,使得能够探索远超传统基准范围的数据语料库。在这一领域的显著工作包括DINOv2、MAWS和AIM。DINOv2通过在LDV-142M数据集上扩展对比学习iBot方法,实现了生成自监督特征的最新性能。MAWS则研究了掩码自动编码器(MAE)在十亿图像上的扩展。AIM探讨了类似于BERT的自回归视觉预训练在视觉Transformer中的可扩展性。与这些主要聚焦于通用图像预训练或零样本图像分类的方法不同,Sapiens采取了一个截然不同的人类中心方法:Sapiens的模型利用大量的人类图像进行预训练,随后针对一系列与人类相关的任务进行微调。在计算机视觉领域,追求大规模3D人类数字化仍然是一个关键目标。
在受控或工作室环境中取得了显著进展,但将这些方法扩展到非受控环境仍然面临挑战。为了解决这些挑战,开发能够处理多个基本任务的多功能模型至关重要,例如在自然环境中的关键点估计、身体部位分割、深度估计和表面法线预测等任务。在这项工作中,Sapiens旨在开发能够泛化到真实环境中的模型,解决这些关键的视觉任务。
目前,最大的公开语言模型包含超过1000亿个参数,而常用的语言模型则大约包含70亿个参数。相比之下,尽管视觉Transformer(ViT)与语言模型具有类似的架构,但在参数规模上的扩展尚未取得同样的成功。尽管已有一些显著的尝试,例如开发在文本和图像上训练的密集型ViT-4B,以及稳定训练ViT-22B的技术,但目前常用的视觉主干网络的参数规模仍然在3亿到6亿之间,主要在大约224像素的图像分辨率上进行预训练。类似地,现有的基于Transformer的图像生成模型(如DiT)的参数量也少于7亿,并在高度压缩的潜在空间中运行。
为弥补这一差距,Sapiens推出了一系列大型、高分辨率的ViT模型,这些模型在数百万张人类图像上以1024像素的原生分辨率进行预训练。
Sapiens推出了一系列针对四大核心人类视觉任务的模型:2D姿势估计、身体部位分割、深度估计和表面法线预测。Sapiens模型原生支持1K高分辨率推理,并且通过对预训练于超过3亿张真实环境中的人类图像的模型进行简单的微调,能够轻松适应个别任务。Sapiens发现,在相同的计算预算下,基于经过精心筛选的人类图像数据集进行自监督预训练,能够显著提升多种人类相关任务的性能。即使在标注数据稀缺或完全依赖合成数据的情况下,这些模型依然展现了出色的泛化能力。简洁的模型设计还带来了可扩展性——随着参数数量从3亿增加到20亿,模型在各个任务上的性能不断提升。Sapiens在多个以人为中心的基准测试中超越了现有的基线,在多个领域的前沿研究成果上取得了显著提升:在Humans-5K(姿势)上实现了7.6 mAP,在Humans-2K(部位分割)上达到了17.1 mIoU,在Hi4D(深度)上相对RMSE提高了22.4%,在THuman2(法线)上相对角度误差降低了53.5%。
Sapiens:人类视觉模型的突破
近年来,在生成逼真的2D和3D人类模型方面取得了显著进展。这些方法的成功很大程度上归功于各种资产的准确估计,如2D关键点、精细身体部位分割、深度和表面法线。然而,准确估计这些资产仍然是一个活跃的研究领域,并且为了提升个别任务的性能,复杂的系统往往阻碍了更广泛的应用。此外,获取真实环境中的准确标注数据规模化十分困难。Sapiens的目标是提供一个统一的框架和模型,在真实环境中推断这些资产,为各种人类相关应用提供广泛支持。
Sapiens提出,人类中心模型应满足三个标准:泛化能力、广泛适用性和高保真度。泛化能力确保模型在未见过的条件下依然具有鲁棒性,能够在各种环境中稳定表现。广泛适用性意味着模型的多功能性,适用于多种任务,且只需进行最少的修改。高保真度则表示模型能够生成精确的、高分辨率的输出,这对于准确生成与人类相关的任务至关重要。本文详细介绍了具备这些特性的模型,统称为Sapiens。
根据研究见解,Sapiens通过利用大规模数据集和可扩展的模型架构来实现泛化能力。为实现广泛适用性,Sapiens采用了预训练后微调的策略,使模型在完成预训练后能够通过最少的调整适应具体任务。这一方法引发了一个关键问题:哪种类型的数据对预训练最有效?在计算能力有限的情况下,是应尽可能收集更多的人类图像,还是使用未经精心筛选的数据集来更好地反映现实世界的多样性?现有方法通常在下游任务的背景下忽视了预训练数据的分布。为了研究预训练数据分布对人类相关任务的影响,Sapiens收集了Humans-300M数据集,包含3亿张多样化的人类图像。这些未标注的图像用于从零开始预训练一系列视觉Transformer,参数规模从3亿到20亿不等。
在众多从大型数据集中学习通用视觉特征的自监督方法中,Sapiens选择了掩码自动编码器(MAE)方法,因其预训练的简洁性和效率。与对比学习或多次推理策略相比,MAE使用单次推理模型,允许在相同计算资源下处理更大体量的图像。为了实现更高的保真度,Sapiens在预训练中将原生输入分辨率提升至1024像素,相比现有最大规模的视觉主干网络,浮点运算(FLOPs)增加了大约4倍。每个模型预训练处理了1.2万亿个tokens。在针对人类相关任务进行微调时,Sapiens采用了一致的编码器-解码器架构。编码器使用预训练权重初始化,而解码器作为轻量级、任务特定的头部模块,则随机初始化。随后,对编码器和解码器进行端到端的微调。Sapiens聚焦于四个关键任务:2D姿势估计、身体部位分割、深度估计和法线估计,如下图所示。

与以往研究一致,Sapiens确认了标注质量对模型在真实环境中表现的关键影响。公共基准测试通常包含噪声标签,在模型微调过程中提供不一致的监督信号。同时,利用精细且准确的标注对于实现Sapiens的核心目标——3D人类数字化——至关重要。为此,Sapiens提出了一套密度更高的2D全身关键点集用于姿势估计,并扩展了身体部位分割的详细分类词汇,超越了之前数据集的范围。具体而言,Sapiens引入了一套涵盖身体、手、脚、表面和面部的308个关键点集合。此外,Sapiens将分割类别词汇扩展至28个类别,涵盖了头发、舌头、牙齿、上下嘴唇和躯干等身体部位。
为了确保标注的质量和一致性以及高度的自动化,Sapiens使用了多视角捕捉设置来收集姿势和分割标注。同时,Sapiens利用以人为中心的合成数据进行深度和法线估计,通过RenderPeople的600个精细扫描生成高分辨率深度图和表面法线。Sapiens证明了,领域特定的大规模预训练结合有限但高质量的标注,能够实现鲁棒的真实环境泛化。总体而言,Sapiens的方法展示了一种有效的策略,可以开发出高度精确的判别模型,能够在真实场景中表现出色,而无需收集昂贵且多样化的标注集。
人类智慧:方法与建筑
Sapiens采用掩码自动编码器(MAE)方法进行预训练。模型在部分观测的条件下,学习重建原始的人类图像。与所有自动编码器类似,Sapiens的模型包含一个编码器,用于将可见图像映射到潜在表示;以及一个解码器,用于从该潜在表示中重建原始图像。预训练数据集包括单人和多人图像,每张图像都调整为具有固定比例的正方形大小。类似于ViT,图像被划分为固定大小的非重叠规则补丁,一部分补丁被随机选择并遮盖,剩下的部分保持可见。训练期间,遮盖补丁与可见补丁的比例(即遮盖率)保持固定。
Sapiens的模型在不同图像特征上表现出广泛的泛化能力,包括比例、裁剪、主体的年龄和种族,以及主体数量。与标准ViT相比,模型中的每个补丁token仅占图像面积的0.02%,而标准ViT为0.4%,这意味着Sapiens模型具有更加细粒度的token间推理能力。即使将遮盖率提高至95%,Sapiens的模型仍能在保留样本上实现合理的人体结构重建。下图展示了Sapiens预训练模型在未见过的人类图像上的重建效果。

此外,Sapiens在预训练过程中使用了一个大型的专有数据集,该数据集包含约10亿张真实环境中的图像,专注于人类图像。预处理步骤包括剔除带有水印、文字、艺术描绘或不自然元素的图像。随后,Sapiens使用现成的人体边界框检测器过滤图像,保留检测得分高于0.9且边界框尺寸超过300像素的图像。数据集中有超过2.48亿张图像包含多个人物。
2D姿势估计
在Sapien框架中,编码器和解码器通过P在多种骨架上进行微调,包括K=17 [67]、K=133 [55],以及一个全新高度详细的骨架(K=308),如下图所示。
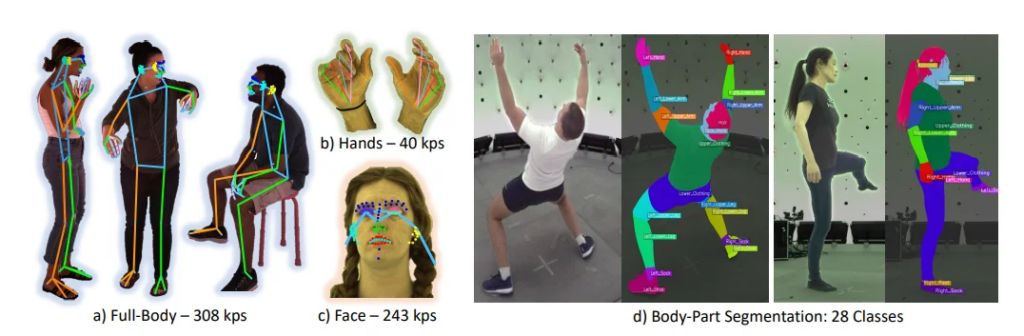
与现有最多包含68个面部关键点的格式相比,Sapien的标注包含243个面部关键点,包括眼睛、嘴唇、鼻子和耳朵周围的代表性点。这种设计旨在细致捕捉现实世界中面部表情的微妙细节。通过这些关键点,Sapien框架手动标注了在室内捕捉环境下获得的100万张4K分辨率图像。与之前的任务类似,我们将法线估计器N的解码器输出通道设为3,对应每个像素法线向量的xyz分量。生成的合成数据也用于法线估计的监督学习。

Sapien:实验与结果
Sapiens-2B使用1024张A100 GPU进行18天的预训练,采用PyTorch框架。所有实验均使用AdamW优化器。学习策略包括短暂的线性预热阶段,随后进行余弦退火预训练以及线性衰减微调。所有模型均从头开始在1024 × 1024分辨率下预训练,补丁大小为16。在微调时,输入图像会调整为4:3的比例,即1024 × 768。Sapiens应用了标准的数据增强方法,如裁剪、缩放、翻转和光度失真。在分割、深度和法线预测任务中,添加了来自非人类COCO图像的随机背景。
重要的是,Sapiens通过差异化学习率来保持泛化能力,初始层使用较低的学习率,后续层逐步提高学习率。逐层学习率衰减设置为0.85,编码器的权重衰减为0.1。
Sapiens的设计规格详述如下表。采用特定的方法,Sapiens优先考虑通过增加模型宽度而非深度进行扩展。值得注意的是,虽然Sapiens-0.3B模型在架构上与传统的ViT-Large相似,但由于其更高的分辨率,浮点运算量(FLOPs)是其20倍之多。
Sapiens通过高保真标注微调了面部、身体、脚部和手部(K = 308)的姿态估计。训练过程中,Sapiens使用包含100万张图像的训练集,而评估使用名为Humans5K的测试集,包含5000张图像。评估采用自上而下的方式,Sapiens使用现成的边界框检测器进行单人姿态推断。表3展示了Sapiens模型与现有方法在全身姿态估计上的对比。所有方法均在Sapiens的308个关键点词汇表与COCO-WholeBody的133个关键点词汇表之间的114个共同关键点上进行评估。Sapiens-0.6B在精度上超过了当前最先进的DWPose-l,提升了+2.8 AP。与利用复杂的学生-教师框架和特征蒸馏专门为任务设计的DWPose不同,Sapiens采用的是通用的编码器-解码器架构,并结合大规模的以人为中心的预训练。
有趣的是,即使参数数量相同,Sapiens模型的表现也明显优于同类模型。例如,Sapiens-0.3B在AP值上超过了VitPose+-L,提升了+5.6 AP,而Sapiens-0.6B则比VitPose+-H高出+7.9 AP。在Sapiens系列模型中,结果显示模型的尺寸与性能成正相关关系。Sapiens-2B以61.1 AP创造了新的业界标杆,比之前的先进方法提高了+7.6 AP。尽管Sapiens使用的是来自室内捕捉工作室的标注进行微调,但其在实际场景中的泛化能力表现出色,如下图所示。

Sapiens使用包含28个类别的分割词汇进行微调和评估。训练集包含10万张图像,测试集Humans-2K包含2000张图像。在相同的训练集上,Sapiens与现有的身体部位分割方法进行了对比,并使用每种方法建议的预训练检查点作为初始化。与姿态估计类似,Sapiens在分割任务中也展示了出色的泛化能力,如下表所示。
有趣的是,即使是最小的模型Sapiens-0.3B,由于其更高的分辨率和大规模以人为中心的预训练,其分割性能也优于现有的先进方法,如Mask2Former和DeepLabV3+,提升了12.6 mIoU。此外,随着模型规模的增加,分割性能也进一步提高。Sapiens-2B在测试集上取得了最佳表现,达到了81.2 mIoU和89.4 mAcc。下图展示了Sapiens模型的定性结果。

总结
Sapiens代表了推动以人为中心的视觉模型向基础模型发展的重要一步。Sapiens模型在多种以人为中心的任务中展现了强大的泛化能力。其领先的表现归因于以下几个方面:(i) 在专门为理解人类行为而定制的精选数据集上进行大规模预训练,(ii) 使用高分辨率和高容量的视觉Transformer骨干网络进行扩展,(iii) 对增强的工作室和合成数据进行高质量标注。Sapiens模型有潜力成为众多下游任务中的关键构建模块,并为更广泛的社区提供高质量的视觉骨干网络。