

近年来,Meta的首席AI科学家Yann LeCun一直在谈论深度学习系统,该系统可以在很少或没有人类帮助的情况下学习世界模型。现在,随着 Meta 刚刚发布了 I-JEPA 的第一个版本,这一愿景正在慢慢实现,I-JEPA 是一种类人的人工智能模型,它可以比现有模型更准确地分析和完成缺失的图像。
初步测试表明,I-JEPA在许多计算机视觉任务上表现强劲。它也比其他最先进的模型更有效。Meta 已经开源了训练代码和模型,并将在下周的计算机视觉和模式识别会议 (CVPR) 上展示 I-JEPA 。
自我监督学习
自我监督学习的想法受到人类和动物学习方式的启发。我们只是通过观察世界来获得我们的大部分知识。同样,人工智能系统应该能够通过原始观察来学习,而无需人类标记他们的训练数据。
自我监督学习在人工智能的某些领域取得了长足的进步,包括生成模型和大型语言模型(LLM)。2022 年,LeCun 提出了“联合预测嵌入架构”(JEPA),这是一种可以学习世界模型和常识等重要知识的自监督模型。
DALL-E 和 GPT 等生成模型旨在进行精细预测。例如,在训练期间,文本或图像的一部分被遮挡,模型尝试预测确切的缺失单词或像素。试图填写每一点信息的问题在于,世界是不可预测的,模型经常卡在许多可能的结果中。这就是为什么在创建详细的对象(如手)时会看到生成模型失败的原因。
相比之下,JEPA 尝试学习和预测高级抽象,而不是像素级细节,例如场景必须包含的内容以及对象如何相互关联。这种方法使模型在学习环境的潜在空间时不易出错,成本也大大降低。
I-JEPA
I-JEPA 是 LeCun 提出的架构的基于图像的实现。它通过使用“抽象的预测目标”来预测缺失的信息,这些目标可能会消除不必要的像素级细节,从而引导模型学习更多的语义特征。
I-JEPA使用视觉转换器(ViT)对现有信息进行编码,视觉转换器是LLM中使用的变压器架构的一种变体,但针对图像处理进行了修改。然后,它将此信息作为上下文传递给预测器 ViT,该预测器为缺失的部分生成语义表示。
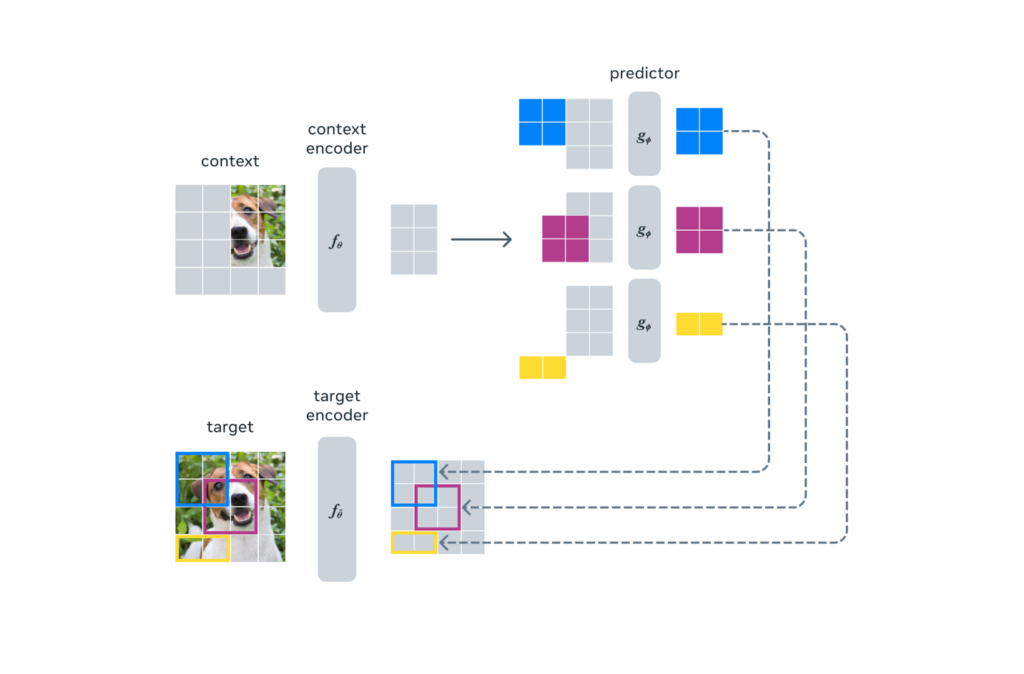
Meta的研究人员训练了一个生成模型,该模型根据I-JEPA预测的语义数据创建草图。在下面的图像中,I-JEPA被赋予蓝色框外的像素作为上下文,并预测蓝色框内的内容。然后,生成模型创建了I-JEPA预测的草图。结果表明,I-JEPA的抽象与场景的真实性相匹配。

虽然I-JEPA不会生成逼真的图像,但它可以在机器人和自动驾驶汽车等领域有许多应用,在这些领域中,AI代理必须能够理解其环境并处理一些非常合理的结果。
一个非常有效的模型
I-JEPA 的一个明显优势是它的内存和计算效率。预训练阶段不需要其他类型的自监督学习方法中使用的计算密集型数据增强技术。研究人员能够在72小时内使用16个A100 GPU,就训练出了一个632M参数的视觉Transformer模型,约为其他技术所需参数的十分之一。
“根据经验,我们发现I-JEPA可以在不使用手工制作的视图增强的情况下学习强大的现成语义表示,”研究人员写道。
他们的实验表明,I-JEPA还需要更少的微调,以在计算机视觉任务(如分类,对象计数和深度预测)上优于其他最先进的模型。研究人员能够使用1%的训练数据在ImageNet-1K图像分类数据集上微调模型,每个类仅使用12到13张图像。
鉴于互联网上未标记数据的高可用性,I-JEPA 等模型对于以前需要大量手动标记数据的应用程序来说非常有价值。