


生成模型的最新发展引领了文本到图像生成模型的新时代,标志着它们在性能方面取得了重大进展。然而,这些模型一直在全面解释详细的图像描述方面遇到困难,经常错误解释或忽略特定的词语,导致生成的输出结果产生混淆。
为了解决提示跟随问题,在一篇新论文《通过更好的字幕改进图像生成(Improving Image Generation with Better Captions)》中,OpenAI和微软的研究团队介绍了DALL-E 3,这是一种尖端的文本到图像生成系统。这一创新性模型在提示跟随、连贯性和美感方面具有卓越的性能,展示了它在与现有对手竞争中的竞争优势。

研究团队认为,现有文本到图像模型的关键瓶颈在于与训练图像配对的文本描述的质量。他们的解决方案涉及增强这些字幕以全面解决这个问题。
为执行这一策略,研究人员首先构建了一个强大的图像字幕系统,能够生成高度详细和精确的图像描述。然后,这个改进后的字幕系统被应用于数据集,从而产生更具信息性的图说。这些精炼的图说成为了训练文本到图像模型的基础,标志着流程中的一个关键步骤。
他们开发了一种新颖的、具有描述性的图像字幕系统,并在特别考虑在训练期间使用合成字幕的情况下,精确测量了它对生成模型的影响。此外,研究人员建立了一套评估指标的强大基准性能档案,旨在衡量提示跟随,确保他们的发现可复制和可靠。
最终的DALL-E 3成为了新一代文本到图像生成器,与其前身DALL-E 2相比,带来了多项改进。虽然DALL-E 3的复杂技术细节不在本文的范围之内,但它强调通过训练精心生成的描述性字幕来实现的增强提示跟随能力的全面评估。此外,研究团队慷慨地分享了这些评估的样本和代码,从而促进了一个有利于继续优化文本到图像系统这一关键方面的环境。
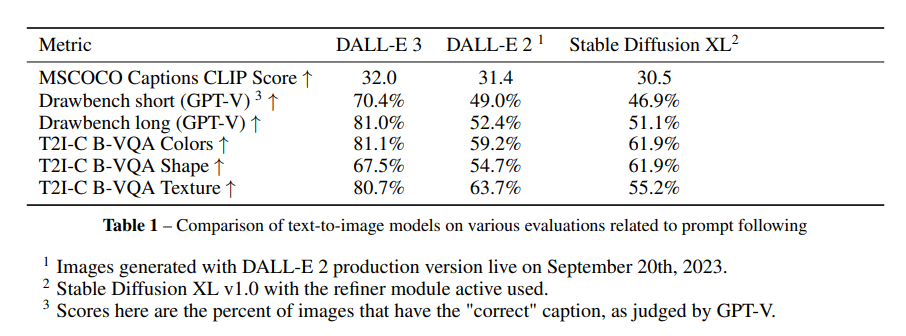

在一项比较分析中,DALL-E 3与DALL-E 2和带有细化模块的Stable Diffusion XL 1.0进行了对比。在所有的评估指标中,DALL-E 3始终优于其前身,这表明通过使用高度详细的生成图像字幕进行训练,文本到图像模型的提示跟随能力确实可以显著增强。这一文本到图像生成领域的突破为未来的研究和应用带来了巨大的潜力。