
过去一年中,AI工具的爆炸式增长对数字营销人员,尤其是SEO从业者产生了巨大影响。鉴于内容创作的耗时和成本,营销人员开始借助AI进行辅助创作,但效果参差不齐。尽管存在伦理问题,但一个反复出现的问题是:“搜索引擎能检测出我的AI内容吗?”
这个问题被认为尤为重要,因为如果答案是否定的,那么许多其他关于是否以及如何使用AI的问题都将无效。
机器生成内容历史悠久
尽管机器生成或辅助创作内容的频率前所未有,但它并不是全新的,也不总是负面的。
新闻网站必须第一时间报道突发事件,他们长期以来一直利用来自各种来源的数据,比如股市和地震仪,以加快内容创作速度。
例如,发布一篇以下内容的机器人文章是事实正确的:
“今天早晨在[地点、城市]检测到[震级]的地震,这是自[上次事件的日期]以来的首次地震。更多消息即将跟进。”
这样的更新对于需要尽快获取信息的读者也是有帮助的。
另一方面,我们也看到许多“黑帽”机器生成内容的实例。
谷歌多年来一直谴责使用马尔科夫链生成文本或进行低质量内容旋转,因为这被认为是“自动生成的页面,没有提供任何附加价值”。
特别有趣的是,“附加价值”这一概念对于一些人来说可能仍然是混淆或灰色地带。
LLM(大型语言模型)如何增加价值?
由于受到GPT x 大语言模型和经过优化的AI聊天机器人ChatGPT的关注,AI内容的流行度大幅上升,ChatGPT改进了对话交互。
在不涉及技术细节的情况下,这些工具需要考虑几个重要观点:
- 生成的文本是基于概率分布的。 例如,如果你写下:“作为一个SEO,很有趣的是…”,LLM会查看所有的标记,并尝试基于它的训练数据计算下一个最可能的单词。从某种程度上说,你可以把它想象成你手机预测文本的一个非常高级的版本。
- ChatGPT是一种生成式人工智能。 这意味着输出是不可预测的。它包含一个随机元素,对于相同的提示可能会有不同的响应。
当你理解了这两点后,很明显,像ChatGPT这样的工具并没有任何传统的知识或“知道”任何事情。这个缺点是导致所有错误或所谓的“幻觉”的根本原因。大量的记录输出表明,这种方法会产生错误结果,并导致ChatGPT反复自相矛盾。
这就对AI写作文本“增加价值”的一致性产生了严重的疑虑,因为可能会频繁出现幻觉。
根本原因在于LLM如何生成文本,这不会轻易得到解决,除非采用新的方法。这是一个重要的考虑因素,特别是对于涉及“你的金钱,你的生活”(YMYL)主题的内容,如果不准确,可能会对人们的财务或生活造成实质性的伤害。
像《Men’s Health》和《CNET》等主要出版物在今年被发现发布了事实不准确的AI生成信息,引起了人们的关注。出版商并不是唯一面临这个问题的人,谷歌在管理与“你的金钱,你的生活”内容相关的搜索生成体验(SGE)内容方面也面临困难。
尽管谷歌表示会谨慎处理生成的答案,并特别举例说明“不会显示有关给孩子吃退热药的问题,因为这涉及医疗领域”,但实际上SGE在被问及此问题时明显做出了这样的回答。
谷歌的SGE和MUM
谷歌明确认为机器生成内容有助于回答用户的查询。自从2021年5月谷歌宣布MUM(多任务统一模型)以来,他们就暗示过这一点。
MUM的一个挑战是基于数据显示,人们在处理复杂任务时平均会发出八个查询。在初始查询中,搜索者会获得一些附加信息,从而引发相关的搜索,并展示新的网页来回答这些查询。
谷歌提出了这样一个问题:如果他们能够将初始查询与用户的后续问题相结合,并利用他们的索引知识生成完整的答案,会怎么样呢?
如果这样做成功了,虽然对用户来说可能很棒,但它实际上会淘汰许多SEO依赖的“长尾”或零搜索量关键词策略,以在搜索引擎结果页面(SERPs)中站稳脚跟。
假设谷歌可以识别适合采用AI生成答案的查询,许多问题可能被认为是“解决了”。
这引出了一个问题…
如果谷歌可以通过预先生成的答案使用户留在他们的搜索生态系统中,并且自己生成答案,为什么还要显示搜索者的网页呢?
谷歌有财务动机让用户留在他们的生态系统内。我们已经看到了各种各样的方法来实现这一点,从特色摘要到在搜索结果页面搜索航班。假如谷歌认为您的生成内容在提供的价值上没有超过他们已有的内容,那么这实际上只是一个搜索引擎的成本与效益的问题。他们能通过吸收生成答案的费用并让用户等待来从长远来看获得更多收入,而不是迅速且廉价地将用户发送到他们已知的网页吗?
检测AI内容
随着ChatGPT的使用激增,出现了许多“AI内容检测器”,它们允许您输入文本内容,并输出一个百分比分数,这也是问题所在。
虽然不同的检测器在如何标记这个百分比得分上存在一些差异,但它们几乎都会给出相同的输出:对于整个提供的文本是AI生成的百分比确定性。
这导致了混淆,例如当百分比被标记为“75% AI / 25% 人类”。很多人会误解为“这个文本是由75%的AI和25%的人类撰写的”,实际上它的意思是,“我对这段文本是由AI撰写的有75%的确定性”。
这种误解导致一些人提供如何调整文本输入使其“通过”AI检测器的建议。例如,使用双感叹号(!!)是一个非常人类的特点,所以将其添加到一些AI生成的文本中将导致AI检测器给出“99%以上的人类”分数。
然后误解为你已经“愚弄”了检测器。
但这是检测器完美运行的一个例子,因为提供的文本不再完全由AI生成。
不幸的是,这种误导性的结论能够“愚弄”AI检测器,也常常与谷歌等搜索引擎无法检测到AI内容混为一谈,使网站所有者产生错误的安全感。
谷歌在AI内容上的政策和行动
谷歌对于AI内容的声明过去一直含糊不清,给了他们在执行方面灵活的空间。
然而,今年在谷歌搜索中心发布了更新的指导方针,明确表示:“我们的重点是内容的质量,而不是内容的产生方式。”
即使在此之前,谷歌搜索联络员丹尼·沙利文在Twitter上的对话中也明确表示,他们“没有说AI内容是坏的”。
谷歌列举了AI如何生成有用内容的具体例子,例如体育比分、天气预报和转录。
很明显,谷歌更关心输出结果,而不是实现方式,坚决强调“为了操纵搜索结果排名而生成内容违反我们的垃圾邮件政策。”
打击搜索结果操纵是谷歌拥有多年经验的领域,声称其系统的改进(如SpamBrain)使99%的搜索“无垃圾邮件”,其中包括UGC垃圾邮件、爬虫、伪装和各种形式的内容生成。很多人进行了测试,看看谷歌对于AI内容的反应,以及他们在质量上的底线。
在ChatGPT推出之前,创建了一个网站,其中包含由无监督的GPT3模型主要生成的10,000页内容,回答关于视频游戏的“人们还在问”的问题。在最小的链接情况下,该网站迅速被索引,并持续增长,每月吸引数千名访问者。然而,在2022年的两次谷歌系统更新,即“有益内容更新”和随后的“垃圾邮件更新”中,谷歌突然几乎完全屏蔽了该网站。
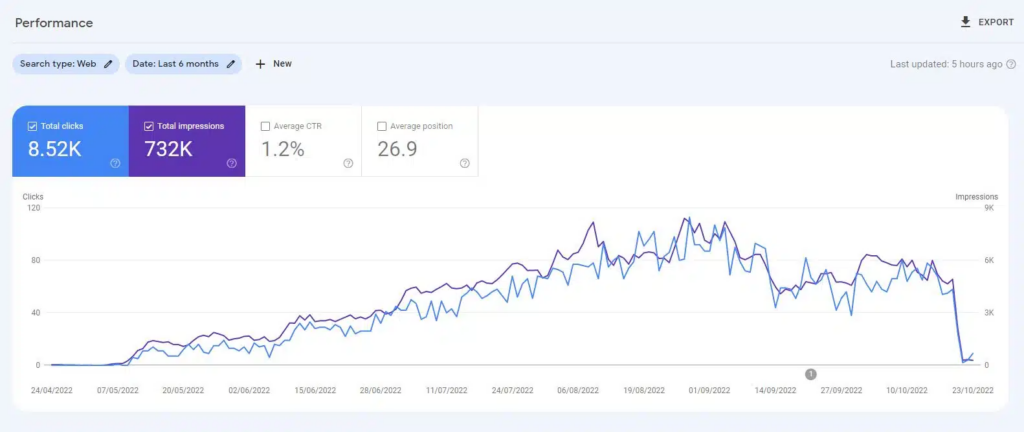
从这样的实验中得出“AI内容不起作用”的结论是错误的。
然而,这证明在那个特定的时候,谷歌:
- 没有将无监督的GPT-3内容分类为“优质”内容。
- 可以通过其他一系列信号检测和删除这样的结果。
要得到最终答案,您需要提出更好的问题。
根据谷歌的指南,大家对搜索系统、SEO实验和常识的了解,”搜索引擎能否检测到AI内容?”很可能是一个错误的问题。
最多,这只是一个非常短期的观点。
在大多数主题中,LLM在准确性和满足谷歌的E-A-T标准方面难以持续产生“高质量”的内容,尽管它们可以访问实时网络以获得超出其训练数据的信息。AI在为以前内容匮乏的查询生成答案方面取得了重大进展。但随着谷歌为SGE设定更高远的长期目标,这一趋势可能会逐渐消失。
预计重点将回归到更长形式的专家内容,谷歌的知识系统将提供答案来满足许多长期查询,而不是引导用户前往众多小型网站。